Alors que le Syndicat national de l’édition (SNE) – qui regroupe les majors françaises du livre parmi plus de 700 membres – organise le 42e Festival du Livre de Paris (12-13 avril), les IA génératives s’invitent parmi les « auteurs » avec des ouvrages dont elles ont écrit tout ou partie. Disruptif.
 Pendant que l’industrie du livre fait son festival à Paris, l’intelligence artificielle vient jouer les trouble-fête en s’immisçant de plus en plus dans le monde de l’édition. Une nouvelle génération d’éditeurs, férus de technologies, s’apprêtent à disrupter la production de livres en accélérant leur mise sur le marché grâce notamment à l’IA générative pour raccourcir le temps de l’écriture et les éditer le plus rapidement possible auprès des lecteurs.
Pendant que l’industrie du livre fait son festival à Paris, l’intelligence artificielle vient jouer les trouble-fête en s’immisçant de plus en plus dans le monde de l’édition. Une nouvelle génération d’éditeurs, férus de technologies, s’apprêtent à disrupter la production de livres en accélérant leur mise sur le marché grâce notamment à l’IA générative pour raccourcir le temps de l’écriture et les éditer le plus rapidement possible auprès des lecteurs.
L’IA édite un livre en quelques jours
« Le monde de l’édition a peu changé depuis l’époque de Gutenberg et appelle à la transformation », prévient la startup américaine Spines (ex-BooxAI), cofondée en 2021 par l’Israélien Yehuda Niv (photo de gauche). Spines est une plateforme d’édition basée sur l’intelligence artificielle, qui propose aux auteurs « un moyen facile de publier, distribuer et commercialiser leurs livres, le tout en un seul endroit, en seulement 8 jours, du manuscrit à un titre publié, y compris la relecture, le formatage, la conception de la couverture, la distribution et le marketing sur tous les principaux canaux et plateformes ». Une semaine ! Là où les maisons traditionnelles mettent des mois avant de publier un livre. Yehuda Niv, PDG de la startup basée en Floride (1), et ses équipes veulent « réinventer le futur de l’édition ». « Nous voulons publier jusqu’à 8.000 livres en 2025. L’objectif est d’aider 1 million d’auteurs à publier leurs livres », avait déclaré Yehuda Niv, en novembre dernier à The Bookseller (2).
La plateforme Spines revendique (au 11 avril 2025) plus de (suite)
2.800 auteurs édités. « Il vous suffit de télécharger votre manuscrit et, en quelques jours, de le voir se transformer en un chef-d’œuvre publié et apprécié par les lecteurs du monde entier. Notre IA est comme un éditeur vigilant, scannant méticuleusement votre manuscrit à la recherche de tout problème de grammaire ou de zones qui bénéficieraient d’une amélioration », promet-elle aux auteurs. C’est de l’auto-édition à compte d’auteur boostée à l’IA, moyennant 1.200 à 5.000 dollars, les droits d’auteur lui revenant intégralement. Au Texas cette fois, les jumeaux Mikkelsen – Christian (photo de droite), PDG, et Rasmus, directeur technique, cofondateurs en 2018 de la société d’auto-édition Publishing.com – ont lancé en août 2024 Publishing.ai, leur plateforme logicielle conçue pour « rationaliser le processus d’édition de livres en exploitant l’intelligence artificielle éthique de pointe pour permettre aux auteurs, éditeurs et créateurs de contenu de produire des livres de haute qualité plus rapidement, plus facilement et plus économiquement que jamais » (3). L’IA va prémâcher en quelques minutes le travail de l’auteur, en lui suggérant les idées de livres les plus vendues, avec analyse du lectorat potentiel. Et en quelques heures, un « Manuscript Assistant » va lui produire un brouillon de 30.000 mots, construit selon ses spécifications et prêt pour des touches personnelles. L’IA permet en outre la personnalisation du style d’écriture et du ton en fonction de ce que souhaite l’auteur. Son manuscrit, unique, est alors prêt à être édité ! « Nos outils sont conçus pour améliorer votre créativité, pas la remplacer », assure Rasmus Mikkelsen. Et selon les jumeaux, avec Publishing.ai, « il n’est pas nécessaire d’embaucher de coûteux écrivains fantômes [ghostwriters, ou « nègres » selon la regrettable expression remplacée par « prête-plume », ndlr] »… De leur côté, Microsoft et ByteDance (maison mère de TikTok) sont en embuscades avec leur nouvelle maison d’édition, respectivement 8080 Books et 8th Note Press.
 En France, la « maison d’auto-édition et agence littéraire » Libranova, cofondée en 2014 par Charlotte Allibert (photo ci-contre) et Laure Prételat, « suppose que ce sont plusieurs milliers d’ouvrages qui ont été rédigés par l’IA et publiés en France, notamment via la plateforme Amazon Kindle Direct Publishing ». Le géant du e-commerce autorise chaque compte KDP à publier jusqu’à trois publications par jour (4), afin de limiter l’édition massive facilitée par l’IA, « ce qui implique qu’un compte peut [tout de même, ndlr] générer environ 1.095 titres par an », relèvent-elles.
En France, la « maison d’auto-édition et agence littéraire » Libranova, cofondée en 2014 par Charlotte Allibert (photo ci-contre) et Laure Prételat, « suppose que ce sont plusieurs milliers d’ouvrages qui ont été rédigés par l’IA et publiés en France, notamment via la plateforme Amazon Kindle Direct Publishing ». Le géant du e-commerce autorise chaque compte KDP à publier jusqu’à trois publications par jour (4), afin de limiter l’édition massive facilitée par l’IA, « ce qui implique qu’un compte peut [tout de même, ndlr] générer environ 1.095 titres par an », relèvent-elles.
« Human Authored » et « Création Humaine »
Il y a un an, Libranova s’est associé au label payant « Création Humaine » (5), lancé en 2023 par Nicolas et Cécile Gorse, pour certifier que le contenu n’a pas été généré par une IA (6). Aux Etats-Unis, en janvier 2025, la Authors Guild a lancé dans le même esprit la certification « Human Authored » (7) pour « préserver l’authenticité de la littérature », ayant constaté que « les livres générés par l’IA inondent les marchés en ligne et ressemblent de plus en plus à des livres d’auteurs humains ». Les maisons d’édition risquent d’en perdre leur latin. @
Charles de Laubier
 Sur les 518,8 millions d’euros de crédits du programme « Expertise, information géographique et météorologie » inscrits dans la loi de finances 2025 promulguée le 15 février dernier (
Sur les 518,8 millions d’euros de crédits du programme « Expertise, information géographique et météorologie » inscrits dans la loi de finances 2025 promulguée le 15 février dernier ( Bouleversement de l’économie de la donnée
Bouleversement de l’économie de la donnée 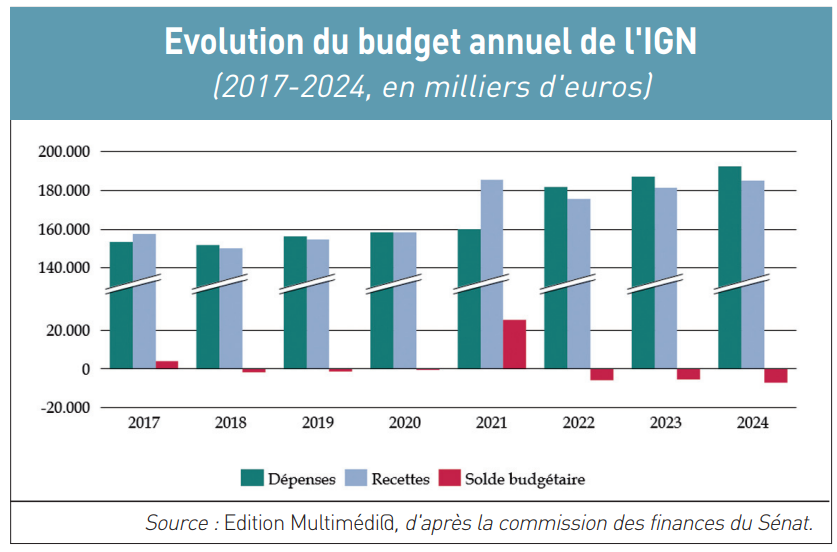
 La suprématie de Google (filiale d’Alphabet) sur le marché mondial des moteurs de recherche reste quasiment inchangée à fin janvier 2025 par rapport à il y a un an, et malgré la déferlante des IA génératives et autres chabots boostés à l’intelligence artificielle. D’après StatCounter, le moteur de recherche Google s’arroge encore 89,78 % de part de marché mondiale dans le search (
La suprématie de Google (filiale d’Alphabet) sur le marché mondial des moteurs de recherche reste quasiment inchangée à fin janvier 2025 par rapport à il y a un an, et malgré la déferlante des IA génératives et autres chabots boostés à l’intelligence artificielle. D’après StatCounter, le moteur de recherche Google s’arroge encore 89,78 % de part de marché mondiale dans le search (