Avec ses 100 millions de visites par mois, seuil atteint en 2025, 20 Minutes – média « 100 % numérique » depuis l’abandon du papier en juillet 2024 – bascule sous « conditions » dans les mains du groupe belge Rossel (Le Soir, La Meuse, …), bien implanté aussi dans le Nord de la France (La Voix du Nord, Courrier Picard, …).
 C’est une question de « semaines » pour finaliser l’opération, a priori en mars. Le groupe familial belge Rossel, détenu par la famille Hurbain depuis sa création en 1887, passe un cap historique en France en prenant le contrôle du quotidien national français 20 Minutes. Il ne détenait jusqu’alors dans l’Hexagone que des quotidiens régionaux comme La Voix du Nord, Courrier Picard ou Paris Normandie, ainsi que des hebdomadaires locaux, des magazines, des radios (Radio Contact et Champagne FM) et la télévision locale Wéo (1).
C’est une question de « semaines » pour finaliser l’opération, a priori en mars. Le groupe familial belge Rossel, détenu par la famille Hurbain depuis sa création en 1887, passe un cap historique en France en prenant le contrôle du quotidien national français 20 Minutes. Il ne détenait jusqu’alors dans l’Hexagone que des quotidiens régionaux comme La Voix du Nord, Courrier Picard ou Paris Normandie, ainsi que des hebdomadaires locaux, des magazines, des radios (Radio Contact et Champagne FM) et la télévision locale Wéo (1).
En rachetant les 49,3 % que le groupe français Sipa Ouest-France codétenait à part égale à la sienne (hormis 1,4 % d’actions autodétenues) dans la société 20 Minutes France basée à Levallois-Perret dans les Hauts-de-Seine, le groupe de médias bruxellois a désormais les coudées franches pour continuer à concurrencer les quotidiens nationaux français Le Monde, Le Figaro, Le Parisien, ou encore Libération. Quotidien gratuit lancé en France par le groupe norvégien Schibsted il y aura 24 ans le 15 mars 2026, 20 Minutes – présenté alors comme « un nouveau média complémentaire de la presse classique » s’adressant à « une nouvelle génération de lecteurs qui ne lit pas la presse payante » – s’est imposé rapidement dans le paysage de la presse française. Edité au format papier jusqu’en juillet 2024 (distribué gratuitement dans les grandes villes françaises), 20 Minutes est devenu le premier média numérique le plus consulté.
20 Minutes, en tête des médias en ligne
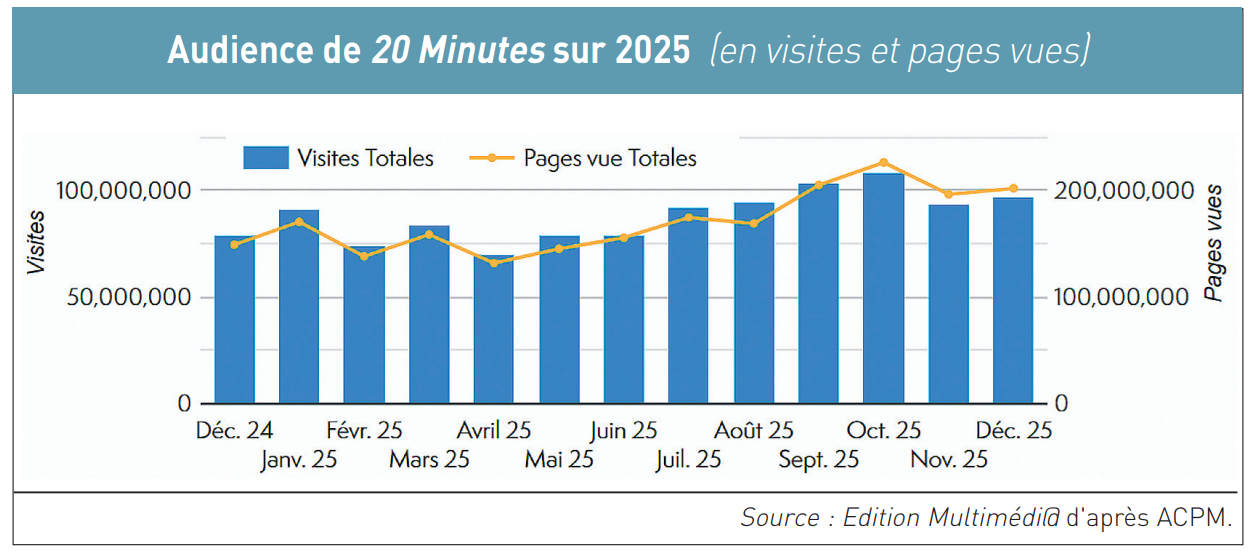
D’après un sondage mené par YouGov pour le Reuters Institute for the Study of Journalism, publié dans le Digital News Report 2025 en juin dernier (2), 20 Minutes – que dirige Sabina Gros (photo de gauche) – arrive en tête des médias numériques les plus fréquentés chaque semaine par les Français (14 %), devant Le Monde à égalité avec TF1 Info (12%) ou encore Franceinfo (11%), laissant même loin derrière Le Parisien à égalité avec Le Figaro (9 %) et même Ouest-France (7 %). Cependant, si l’on se fie cette fois aux audiences en ligne (sites web et applications mobiles) déclarées par les éditeurs eux-mêmes auprès de l’Alliance pour les chiffres de la presse et des médias (ACPM) qui les certifie, 20 Minutes se maintient en 9e position en nombre de visites par mois, et même 7e si l’on met à part Leboncoin et Tele-Loisirs (3), devançant tout de même Le Parisien et Libération. L’audience a même bondi en 2025 de 22,9 %, au point de (suite) franchir pour la première fois la barre des 100 millions de visites par mois en septembre et octobre derniers (4) (voir tableau ci-dessous).
« Conflit social » versus « chantage à l’emploi »
« 20 Minutes deviendra ainsi le média national de référence du groupe Rossel », s’est félicité l’acquéreur belge, du moins en France puisqu’il est aussi éditeur du quotidien national francophone Le Soir dans son pays d’origine, aux côtés des quotidiens régionaux belges La Meuse, Nord Eclair, La Province ou encore La Capitale. Le groupe Rossel, dirigé par Bernard Marchant (photo de droite) qui en est l’administrateur délégué, publie aussi de nombreux titres de presse en France tels que L’Union (diffusé dans l’Aisne, la Marne et les Ardennes), Libération Champagne (dans l’Aube), L’Est Eclair (l’Aube également), L’Ardennais (dans les Ardennes), Nord éclair (dans la région de Lille et dans l’Artois) ou encore Paris Normandie (en Normandie). Le groupe Rossel avait tenté en 2014 de racheter Nice-Matin, cette fois sur la Côte d’Azur, mais le tribunal de commerce de Nice avait préféré la candidature de reprise de la coopérative des salariés – du temps de Bernard Tapie et six ans avant que Xaviel Niel s’en empare grâce à un autre groupe belge, Nethys, qui lui céda ses parts (5).
Mais la perspective de la prise de contrôle de 20 Minutes, annoncée aux salariés par Bernard Marchant, présent le 27 novembre 2025 dans les locaux du journal, ne se fait pas dans un climat apaisé. Le patron de Rossel a posé ses « conditions » : que les syndicats signent un accord de la direction sur les droits d’auteur et les droits voisins (660 euros par an pour chaque journaliste), ce que refusent trois d’entre eux exigeant plus – entre 2.000 et 3.000 euros par an (6), validés par Commission droits d’auteur et droits voisins (CDADV), laquelle dépend de la DGMIC au ministère de la Culture (7). « Nous ne souhaitons pas investir dans une entreprise où il y a un conflit social », avait prévenu Bernard Marchant devant les salariés lors d’une autre réunion début décembre avec, cette fois, le coactionnaire Sipa Ouest-France vendeur, lequel était représenté par son directeur général Fabrice Bakhouche. L’administrateur délégué du groupe Rossel l’a confirmé à l’AFP début décembre (8). Les syndicats de journalistes, qui réfutent le terme de « conflit social » (9), reprochent à ce dernier de faire « un chantage inacceptable » auprès des salariés de 20 Minutes en leur disant que s’il devait payer les droits voisins aux conditions de la CDADV (près de 1 million d’euros seraient dus aux journalistes sur la période 2019-2024), « il mettrait 20 Minutes en cessation de paiement et le titre serait racheté, avec des coupes dans les effectifs à la clé », selon ses propos rapportés par les élus SNJ-CGT, SNJ, SNME-CFDT, CFE-CGC et Filpac-CGT du comité de groupe Rossel France (10).
La plupart des salariés de 20 Minutes avaient alors pris peur et avaient adressé à leurs syndicats une lettre pour leur demander « d’accepter la proposition de Bernard Marchand » et, selon ces derniers, « de toucher une somme cinq fois inférieure à celle à laquelle ils peuvent prétendre grâce à la décision de la CDADV ». Ce que les syndicats SNJ, SNJ-CGT, CFDT-Journalistes et SGJ-FO de 20 Minutes (11), sauf CFE-CGC, épaulés par ceux de Rossel France, refusent « parce qu’accepter le chantage à l’emploi dans un groupe qui perd de l’argent, certes, mais affiche toujours des revenus au-dessus de ceux des autres titres en France, est inacceptable ! » (12). Organisé le 16 janvier 2026 par la direction, un référendum – actuellement contesté en référé, selon nos informations – leur a donné tort. « Le sauvetage du titre [est conditionné] à la diminution drastique de la part des droits voisins des journalistes, en imposant par référendum, un pourcentage de 5 %, alors que la CDADV avait tranché pour 18 % », ont dénoncé les syndicats de journalistes, dont FO le 3 février (13). La justice pourrait être saisie. 20 Minutes compte aujourd’hui moins d’une soixantaine de journalistes, après des dizaines de suppressions de postes.
Sabina Gros remplace Ronan Dubois
Une fois la prise de contrôle finalisée, Sabina Gros sera confirmée comme directrice générale de 20 Minutes France, tout en conservant ses fonctions de directrice générale délégué (COO) de la régie publicitaire Rossel Advertising. Cette ancienne de Reworld Media et d’Unify (TF1) assure l’intérim à la tête de 20 Minutes depuis le départ en novembre 2025 de Ronan Dubois, lequel a essuyé une motion de défiance en 2021 et a été accusé en 2025 de propos transphobes. Il a rebondi en janvier 2026 chez Webedia comme directeur général délégué. @
Charles de Laubier
 Les conclusions de l’avocat général de la Cour de justice de l’Union européenne (CJUE) – le Polonais Maciej Szpunar (photo) – ont été rendues le 10 juillet 2025. L’arrêt est donc attendu entre octobre et janvier prochains. Statistiquement, la CJUE suit les conclusions de l’avocat général dans environ 70 % à 80 % des affaires. En substance : « Les Etats membres peuvent adopter des mesures de soutien pour garantir l’effectivité des droits des éditeurs de presse pour autant que ces mesures ne portent pas atteinte à la liberté contractuelle » (
Les conclusions de l’avocat général de la Cour de justice de l’Union européenne (CJUE) – le Polonais Maciej Szpunar (photo) – ont été rendues le 10 juillet 2025. L’arrêt est donc attendu entre octobre et janvier prochains. Statistiquement, la CJUE suit les conclusions de l’avocat général dans environ 70 % à 80 % des affaires. En substance : « Les Etats membres peuvent adopter des mesures de soutien pour garantir l’effectivité des droits des éditeurs de presse pour autant que ces mesures ne portent pas atteinte à la liberté contractuelle » ( Recours de Meta contre l’Agcom
Recours de Meta contre l’Agcom 
 Ce n’est pas anodin à l’ère du numérique et en pleine déferlante de l’intelligence artificielle : la DG Connect – direction générale des réseaux de communication, du contenu et de la technologie de la Commission européenne – a lancé jusqu’au 21 juin une « enquête sur les pratiques contractuelles touchant le transfert du droit d’auteur et des droits voisins ». Si cette démarche porte sur le secteur de la création et de la culture en général au regard des artistes, elle concerne en particulier les maisons d’édition et leurs contrats avec les auteurs.
Ce n’est pas anodin à l’ère du numérique et en pleine déferlante de l’intelligence artificielle : la DG Connect – direction générale des réseaux de communication, du contenu et de la technologie de la Commission européenne – a lancé jusqu’au 21 juin une « enquête sur les pratiques contractuelles touchant le transfert du droit d’auteur et des droits voisins ». Si cette démarche porte sur le secteur de la création et de la culture en général au regard des artistes, elle concerne en particulier les maisons d’édition et leurs contrats avec les auteurs. C’est le premier coup de gueule de Carine Fouteau (photo), cette journaliste qui a succédé en mars 2024 à Edwy Plenel à la présidence de la Société éditrice de Mediapart. La nouvelle directrice de la publication de Mediapart a dénoncé fin avril « l’opacité des Gafam » en général et « l’absence de transparence » de Google en particulier. Le média d’investigation reproche notamment « les clauses de confidentialité imposées par Google » dans le cadre de l’accord que ce dernier a signé en octobre 2023 avec la Société des droits voisins de la presse (DVP).
C’est le premier coup de gueule de Carine Fouteau (photo), cette journaliste qui a succédé en mars 2024 à Edwy Plenel à la présidence de la Société éditrice de Mediapart. La nouvelle directrice de la publication de Mediapart a dénoncé fin avril « l’opacité des Gafam » en général et « l’absence de transparence » de Google en particulier. Le média d’investigation reproche notamment « les clauses de confidentialité imposées par Google » dans le cadre de l’accord que ce dernier a signé en octobre 2023 avec la Société des droits voisins de la presse (DVP).