Les grandes plateformes « systémiques » concernées par la future régulation du Digital Services Act (DSA) font bonne figure face à l’arsenal législatif qui entrera en vigueur d’ici fin 2023. Google, Amazon, Facebook, Apple ou encore Microsoft devront être plus précautionneux en Europe. Qu’en disent-ils ?

« Nous apprécions les efforts déployés pour créer un marché unique numérique européen plus efficace, clarifier les responsabilités de chacun et protéger les droits en ligne », a déclaré Victoria de Posson (photo de gauche), directrice des affaires publiques de la CCIA Europe, la représentation à Bruxelles de l’association américaine du même sigle, dont sont notamment membres les géants du Net, mais pas Microsoft (
1). Elle « reconnaît le travail acharné des décideurs pour parvenir à cet accord historique », tout en mettant un bémol : « Cependant, un certain nombre de détails importants restent à éclaircir » (
2). C’est le cas des obligations de retrait de contenus notifiés comme illicites.
« Accord politique provisoire » : et après ?
Car ce qui a été signé le 23 avril vers 2 heures du matin (
3), après de longues négociations entamées la veille, n’est encore qu’un « accord politique provisoire » obtenu à l’arrachée entre les négociateurs de la commission « marché intérieur et protection des consommateurs » (Imco), tête de file dans le processus législatif de ce projet de règlement européen sur les services numériques, et le Conseil de l’Union européenne – dont Cédric O représentait la France qui préside l’Union européenne jusqu’au 30 juin prochain. Le DSA en cours de finalisation prévoit de réguler les grandes plateformes numériques dites « systémiques » pour : les obliger à lutter contre le piratage et les contenus illicites, les contraindre à donner accès à leurs algorithmes, les amener à renforcement de la protection des mineurs notamment vis-à-vis des contenus pornographiques ou vis-à-vis de la publicité ciblée fondée sur des données sensibles (orientation sexuelle, religion, origine ethnique, etc.), les forcer à mieux informer les utilisateurs sur la manière dont les contenus leur sont recommandés.
Mais le diable étant dans « les détails importants », la CCIA Europe attend beaucoup de la dernière ligne droite de ce texte unique au monde. Selon les informations de
Edition Multimédi@, ce futur règlement DSA devra être approuvé par le Coreper, à savoir le comité des représentants permanents au Conseil de l’UE, et par l’Imco. « Nous espérons que le vote final en plénière aura lieu en juillet, mais cela doit encore être confirmé. Le vote en plénière sera suivi d’un accord formel au Conseil de l’UE », indique une porte-parole du Parlement européen. Pour l’heure, le texte passe par les fourches caudines des juristes-linguistes pour être finalisé techniquement et vérifié jusqu’à la virgule près. Une fois la procédure terminée, probablement l’été prochain, il entrera en vigueur vingt jours après sa publication au Journal officiel de l’UE – sous la présidence cette fois de la République tchèque – et les règles commenceront à s’appliquer quinze mois après, c’est-à-dire au second semestre 2023. Car un règlement européen s’applique dans sa totalité et directement, contrairement à une directive européenne qui donne des objectifs à atteindre par les Etats membres, en leur accordant un délai de plusieurs mois pour les transposer dans la législation nationale.
Les GAFAM auront le temps (quinze mois) de se préparer pour ne pas tomber sous le coup de cette nouvelle loi européenne. Par ailleurs, il ne faudra pas s’attendre à ce que le voyage prévu du 23 au 27 mai prochain dans la Silicon Valley par une délégation de la commission Imco – pour notamment visiter plusieurs sièges sociaux de Big Tech telles que Meta (ex-Facebook), Google ou Apple – change les données du problème. Cette délégation d’eurodéputés y rencontrera également d’autres entreprises du numérique, des start-up, des universitaires américains ainsi que des représentants du gouvernement. « La mission aux Etats-Unis n’affectera pas l’accord politique déjà conclu avec les autres institutions. Elle sera une occasion d’explorer plus en profondeur les questions actuelles liées aux dossiers en cours sur le marché unique numérique au sein de la commission du marché intérieur (Imco) », nous précise la porte-parole du Parlement européen.
Attention aux libertés fondamentales
Cette escapade au pays des GAFAM sera notamment une opportunité pour les députés d’examiner la législation américaine sur le commerce électronique et les plateformes, en faisant le point sur les négociations récemment conclues en rapport avec les dossiers DSA et DMA (Digital Markets Act, pendant concurrentiel du DSA), ainsi que sur d’autres dossiers en cours comme celui sur l’intelligence artificielle. Également contactée, Victoria de Posson n’attend « pas d’impact sur le DSA » de ce voyage. Reste que le DSA, lui, ne sera pas facile à mettre en oeuvre par les GAFAM tant il touche à la liberté des internautes européens. C’est en tout cas ce que pointe DigitalEurope (ex-Eicta), organisation professionnelle des GAFAM entre autres Big Tech (
4), et également installée à Bruxelles : « Le cadre du DSA crée un ensemble d’obligations à plusieurs niveaux pour différents types et tailles de services Internet, dont certains seront très complexes à mettre en oeuvre parce qu’ils touchent aux droits fondamentaux comme la liberté d’expression. Nous exhortons tous les intervenants à collaborer de façon pragmatique pour obtenir les meilleurs résultats », prévient sa directrice générale, Cecilia Bonefeld-Dahl (photo de droite).
Retrait de contenus : risque de censure
Bien que le futur règlement sur les services numériques aidera, d’après DigitalEurope, à rendre l’Internet plus sûr et plus transparent, tout en réduisant la propagation de contenus illégaux et de produits dangereux en ligne, « la modération du contenu sera toujours difficile, compte tenu des intérêts concurrents en cause » (
5). D’autant que la réglementation d’Internet est un équilibre entre la protection des droits fondamentaux comme la liberté d’expression, d’une part, et la prévention des activités illégales et nuisibles en ligne, d’autre part.
Il y a un an, dans un « position paper » sur le DSA, DigitalEurope se félicitait déjà que « la proposition préserve les principes fondamentaux de la directive sur le commerce électronique, qui ont permis à l’Europe de se développer et de bénéficier d’une économie Internet dynamique ». Et de se dire satisfaite : « Le maintien de principes tels que la responsabilité limitée, l’absence de surveillance générale et le pays d’origine est essentiel à la poursuite de l’innovation et de la croissance de ces services numériques en Europe et sera crucial pour une reprise économique rapide ». Par exemple, le lobby des GAFAM a souligné que le DSA reconnaît que le contenu préjudiciable (mais légal) exige un ensemble de dispositions différent du contenu illégal. Le contenu nuisible et contextuel, difficile à définir, peut être subjectif sur le plan culturel et est souvent juridiquement ambigu. Est apprécié également le fait que le texte impose aux plateformes numériques des « exigences de diligence raisonnable » (signaleurs fiables, traçabilité des négociants et mécanismes de transparence), « de façon proportionnelle et pratique ». De plus, DigitalEurope est favorable pour fournir aux intervenants une transparence significative au sujet des pratiques de modération du contenu et d’application de la loi. « Toutefois, ajoute DigitalEurope, il sera important que les mesures de transparence du DSA garantissent que la vie privée des utilisateurs est protégée, que les mauvais acteurs ne peuvent pas manipuler le système et que les renseignements commerciaux sensibles ne sont pas divulgués » (
6).
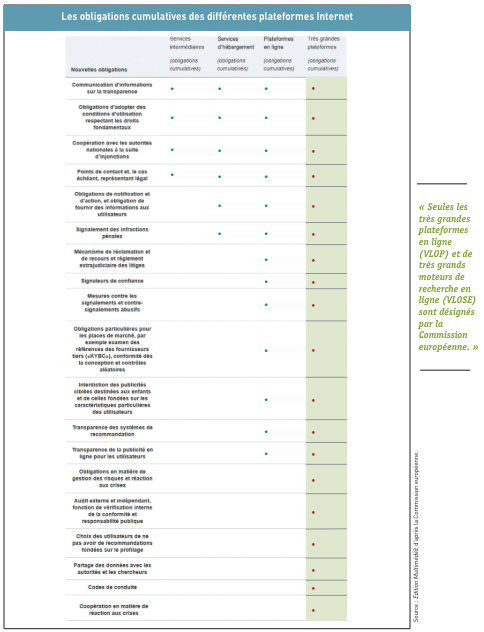
Les intermédiaires de l’écosystème numérique, à savoir les plateformes en ligne que sont les réseaux sociaux et les places de marché, devront prendre des mesures pour protéger leurs utilisateurs contre les contenus, les biens et les services illicites. Une procédure de notification et d’action plus claire permettra aux utilisateurs de signaler du contenu illicite en ligne et obligera les plateformes en ligne à réagir rapidement (les contenus cyberviolents comme le « revenge porn » seront retirés immédiatement). Et ces notifications devront être traitées de manière non-arbitraire et non-discriminatoire, tout en respectant les droits fondamentaux, notamment la liberté d’expression et la protection des données. Quant aux places de marché en ligne, elles seront plus responsables : les consommateurs pourront acheter des produits et services en ligne sûrs et non-illicites, « en renforçant les contrôles permettant de prouver que les informations fournies par les vendeurs sont fiables (principe de “connaissance du client”, (…) notamment via des contrôles aléatoires ».
En cas d’infraction à toutes ces obligations et bien d’autres, des pénalités pécuniaires sont prévues à l’encontre des plateformes en ligne et des moteurs de recherche qui pourront se voir infliger des amendes allant jusqu’à 6% de leur chiffre d’affaires mondial. Concernant les très grandes plateformes (disposant de plus de 45 millions d’utilisateurs), la Commission européenne aura le pouvoir exclusif d’exiger le respect des règles. Algorithmes de recommandation, publicité en ligne, protection des mineurs, choix et désabonnement facilités, compensation des utilisateurs en cas d’infraction, … Une multitude de mesures en faveur du consommateur seront mises en place pour un Internet plus sûr.
Bruxelles dompte la Silicon Valley
Par exemple, les plateformes numériques qui utilisent des « systèmes de recommandation » – basés sur des algorithmes qui déterminent ce que les internautes voient à l’écran – devront fournir au moins une option qui ne soit pas fondée sur le profilage des utilisateurs. « Les très grandes plateformes devront évaluer et atténuer les risques systémiques et se soumettre à des audits indépendants chaque année », est-il en outre prévu (
7). Malgré la distance de 8.894 km qui les séparent, Bruxelles et la Silicon Valley n’ont jamais été aussi proches.
@
Charles de Laubier
 Dans les « affaires courantes » qu’a gérées la ministre démissionnaire de l’Education nationale et de la Jeunesse, Nicole Belloubet (photo), il y avait la présentation le 27 août des grandes orientations de la « rentrée scolaire 2024-2025 ». Parmi les mesures prises afin que tout puisse se passer au mieux pour les près de 12 millions d’élèves qui, en France, ont repris le chemin de l’école, certaines portent sur les usages du numérique, avec l’instauration cette année de la « pause numérique », ainsi que l’apport de l’intelligence artificielle (IA) pour que les enfants et les enseignants puissent l’utiliser à des fins pédagogiques.
Dans les « affaires courantes » qu’a gérées la ministre démissionnaire de l’Education nationale et de la Jeunesse, Nicole Belloubet (photo), il y avait la présentation le 27 août des grandes orientations de la « rentrée scolaire 2024-2025 ». Parmi les mesures prises afin que tout puisse se passer au mieux pour les près de 12 millions d’élèves qui, en France, ont repris le chemin de l’école, certaines portent sur les usages du numérique, avec l’instauration cette année de la « pause numérique », ainsi que l’apport de l’intelligence artificielle (IA) pour que les enfants et les enseignants puissent l’utiliser à des fins pédagogiques. Le règlement européen sur les services numériques (
Le règlement européen sur les services numériques (