La Commission européenne « doute » que Telegram soit en-dessous des 45 millions d’utilisateurs dans les Vingt-sept. Selon nos informations, les analyses de l’audience de la plateforme cryptée du Franco-Russe Pavel Durov pourraient prendre « au moins un mois » avant de lui appliquer éventuellement le DSA.
 « Entre la fin de nos propres analyses que nous sommes en train de mener sur l’audience de Telegram – en distinguant la partie messagerie, qui ne concerne pas le DSA, et la partie groupes ouverts fonctionnant comme un réseau social, relevant du DSA – et le temps qu’il faudra pour s’assurer juridiquement de nos conclusions et de les notifier à l’entreprise Telegram, cela prendra au moins un mois », indique à Edition Multimédi@, Thomas Regnier, porteparole de la Commission européenne. « Nous avons des doutes sur les 41 millions d’utilisateurs en Europe que la plateforme a déclarés en février dernier », ajoute le porte-parole.
« Entre la fin de nos propres analyses que nous sommes en train de mener sur l’audience de Telegram – en distinguant la partie messagerie, qui ne concerne pas le DSA, et la partie groupes ouverts fonctionnant comme un réseau social, relevant du DSA – et le temps qu’il faudra pour s’assurer juridiquement de nos conclusions et de les notifier à l’entreprise Telegram, cela prendra au moins un mois », indique à Edition Multimédi@, Thomas Regnier, porteparole de la Commission européenne. « Nous avons des doutes sur les 41 millions d’utilisateurs en Europe que la plateforme a déclarés en février dernier », ajoute le porte-parole.
Or si la plateforme Telegram atteignait le seuil des 45 millions d’utilisateurs dans les Vingt-sept, elle devrait alors se conformer aux obligations du règlement sur les services numériques, le Digital Services Act (DSA). La Commission européenne a confié à son service Joint Research Center (JRC) le soin d’« étudier la méthodologie de Telegram » (1) dans le calcul du nombre de ses utilisateurs dans l’Union européenne (UE). Bruxelles enquête ainsi discrètement sur Telegram, tandis qu’une procédure judiciaire est en cours en France à l’encontre de son dirigeant fondateur francorusse Pavel Durov (photo), mis en examen le 28 août et placé sous contrôle judiciaire (2).
Telegram, « très grande plateforme en ligne » ?
De son côté, la société Telegram déclare que sa plateforme n’est pas concernée par les obligations du DSA : « Certains éléments non essentiels des services fournis par Telegram peuvent être considérés comme des “plateformes en ligne” dans le cadre du DSA. En août 2024, ces services avaient nettement moins de 45 millions d’utilisateurs actifs mensuels moyens dans l’UE au cours des six mois précédents – ce qui est inférieur au seuil requis pour être désigné comme “très grande plateforme en ligne” » (3).
Telegram indique en outre que les « groupes » d’utilisateurs de sa plateforme, qui en font un véritable réseau social en plus d’être une messagerie cryptée, « comptent jusqu’à 200 000 membres » chacun. Depuis l’entrée en vigueur le DSA le 25 août 2023, sont désignés par la Commission européenne comme « très grande plateforme en ligne », ou VLOP (4), les géants du Net qui totalisent au moins 45 millions d’utilisateurs par mois dans l’UE. Ce seuil est équivalent à 10 % de la population totale des Vingt-sept et doit donc être révisé régulièrement.
« Risques systémiques » et « contenus illicites »
Toute la difficulté pour la Commission européenne est que le calcul restera imprécis, au risque d’être attaquée par Telegram devant la Cour européenne de Justice (CJUE) pour violation du principe de précision consacré par le droit de l’UE. C’est d’ailleurs l’un des arguments du e-commerçant allemand Zalando qui conteste sa désignation comme très grande plateforme en ligne (5). Lorsque Telegram rejoindra le club très fermé de ces plateformes fréquentées mensuellement par au moins 45 millions d’utilisateurs en Europe, la société de Pavel Durov devra alors remplir les obligations renforcées du DSA : évaluer « tout risque systémique », y compris des systèmes algorithmiques, des contenus illicites, ainsi que tout effet négatif sur les droits fondamentaux et la protection de la santé publique et des mineurs. « Les fournisseurs de très grandes plateformes en ligne et de très grands moteurs de recherche en ligne mettent en place des mesures d’atténuation raisonnables, proportionnées et efficaces, adaptées aux risques systémiques spécifiques recensés […], y compris la rapidité et la qualité du traitement des notifications relatives à des types spécifiques de contenus illicites et, le cas échéant, le retrait rapide des contenus qui ont fait l’objet d’une notification ou le blocage de l’accès à ces contenus, en particulier en ce qui concerne les discours haineux illégaux ou la cyberviolence », impose le DSA (6). Telegram pourrait y être soumis dès l’automne prochain, comme le sont déjà Alibaba/AliExpress, Amazon Store, Apple/AppStore, Booking, Facebook, Google Play, Google Maps, Google Shopping, Instagram, LinkedIn, Pinterest, Snapchat, TikTok, Twitter, Wikipedia, YouTube, Bing et Google Search, XVideos, Zalando, Pornhub et Stripchat.
Curieusement, le commissaire européen Thierry Breton en charge du marché intérieur – plutôt prompt à dénoncer les contenus illicites sur le réseau social X (ex-Twitter), qu’il a pris en grippe au point de mettre mal à l’aise la Commission européenne (7) – ne n’est jamais inquiété publiquement de Telegram. Pourtant la réputation de Telegram en matière de contenus illicites et de cybercriminalité est connue dans le monde entier, et a fortiori dans l’UE et bien avant l’entrée en vigueur du DSA il y a un an : contenus criminels, escroquerie, pédocriminalité, revenge porn, trafic de stupéfiants, blanchiment d’argent en bande organisée, apologie du terrorisme, … Il a fallu qu’en France un juge d’instruction du crime organisé mette en examen le patron de la plateforme controversée – pour « refus de communiquer les informations nécessaires aux interceptions autorisées par la loi [française] » – pour que l’on en vienne à se demande pourquoi la Commission européenne n’avait pas elle-même tiré la sonnette d’alarme. Mis en examen en France, Pavel Durov est considéré pénalement comme « personnellement responsable » et donc « complice » des contenus illicites ou cybercriminels présents sur sa plateforme, accusé de ne pas les avoir interdits par un système de modération ou de suppression. Ce que le patron de Telegram réfute, en s’en expliquant dans un post publié le 5 septembre sur sa plateforme : « Telegram a un représentant officiel dans l’UE [la société belge EDSR, ndlr] qui accepte et répond aux demandes de l’UE. Son adresse e-mail (8) a été publiquement rendue disponible (9) pour toute personne dans l’UE qui google [sic] “Telegram EU address for law enforcement”. Les autorités françaises avaient de nombreuses façons de me contacter pour demander de l’aide » (10). Reste qu’il a décidé de coopérer (11).
Pourquoi la Commission européenne n’aurait-elle pas contacté Telegram via EDSR ? Si c’est parce que le seuil des 45 millions d’utilisateurs européens n’a pas encore été établi pour que Bruxelles intervienne directement au nom du DSA, alors pourquoi en deçà de ce seuil l’Arcom, autorité nationale du numérique, ne s’est-elle pas saisie du cas Telegram ? Depuis que la justice pénale française est montée au créneau en incriminant Pavel Durov, Bruxelles botte en touche : « Il n’y a pas eu de communiqué ni de position officielle des commissaires européenne [Thierry Breton ou Margrethe Vestager, ndlr] car la procédure contre le PDG de Telegram lui-même ne concerne pas le DSA », nous a encore expliqué le porte-parole de la Commission européenne. Pour l’instant.
Ses « amis » Emmanuel Macron et Xavier Niel
Le jeune milliardaire (39 ans), né à Léningrad et cofondateur en 2006 du réseau social russe VKontakte, vit à Dubaï (Emirats arabes unis) où il dispose du passeport de « riche investisseur étranger », et y a installé le siège de Telegram. Avant de franciser son nom en 2022 en « Paul du Rove », il a été naturalisé français par décret du 23 août 2021 (12) après avoir eu des rendez-vous avec le président Emmanuel Macron (13). Celui-ci a d’ailleurs tenu à assurer sur X le 26 août que « l’arrestation du président de Telegram sur le territoire français […] n’est en rien une décision politique […] » (14). Tandis que l’AFP indiquait le 29 août que, le soir de son interpellation (le 24 août), Pavel Durov a fait prévenir Xavier Niel de son placement en garde à vue. Sans accord avec la France, il menace de la « quitter ». @
Charles de Laubier
 Claude d’Anthropic sera-t-elle l’IA générative qui pourra détrôner ChatGPT d’OpenAI ? L’avenir dira si la fable du lièvre et de la tortue s’appliquera à ces deux concurrents Alors que ChatGPT d’OpenAI a été lancé le 30 novembre 2022 avec le succès médiatique planétaire que l’on connaît (
Claude d’Anthropic sera-t-elle l’IA générative qui pourra détrôner ChatGPT d’OpenAI ? L’avenir dira si la fable du lièvre et de la tortue s’appliquera à ces deux concurrents Alors que ChatGPT d’OpenAI a été lancé le 30 novembre 2022 avec le succès médiatique planétaire que l’on connaît (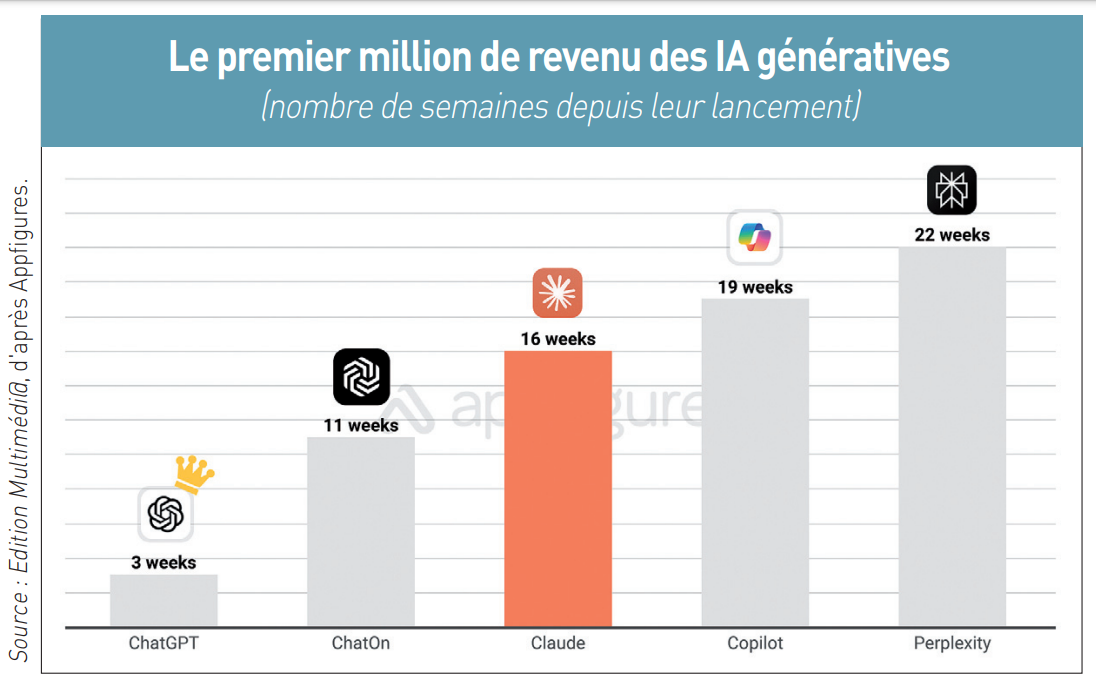 Anthropic a donc plus que jamais une carte à jouer dans la bataille des IA génératives, comme le croit Ariel Michaeli : « Nous estimons que Claude a jusqu’à présent 25.000 abonnés payants. Cela semble beaucoup, mais ChatGPT a ajouté 291.000 nouveaux abonnés payants en juillet [l’IA générative d’OpenAI revendiquant en août plus de 200 millions d’utilisateurs actifs, ndlr]. Pour que Claude ait une chance, il doit apprendre des wrappers et ne pas copier ChatGPT. Si Claude augmente son interface de chat avec des fonctionnalités plus grand public, et s’il promeut son application mobile, alors il pourrait avoir une chance » (
Anthropic a donc plus que jamais une carte à jouer dans la bataille des IA génératives, comme le croit Ariel Michaeli : « Nous estimons que Claude a jusqu’à présent 25.000 abonnés payants. Cela semble beaucoup, mais ChatGPT a ajouté 291.000 nouveaux abonnés payants en juillet [l’IA générative d’OpenAI revendiquant en août plus de 200 millions d’utilisateurs actifs, ndlr]. Pour que Claude ait une chance, il doit apprendre des wrappers et ne pas copier ChatGPT. Si Claude augmente son interface de chat avec des fonctionnalités plus grand public, et s’il promeut son application mobile, alors il pourrait avoir une chance » (