L’émergence fulgurante et extraordinaire de l’intelligence artificielle (IA) soulève aussi des préoccupations légitimes. Sur l’AI Act, un accord entre les Etats membres tarde avant un vote des eurodéputés, alors que 2024 va marquer la fin de la mandature de l’actuelle Commission européenne.
Par Arnaud Touati, avocat associé, Nathan Benzacken, avocat, et Célia Moumine, juriste, Hashtag Avocats.
 Il y a près de trois ans, le 21 avril 2021, la Commission européenne a proposé un règlement visant à établir des règles harmonisées concernant l’intelligence artificielle (IA). Ce règlement européen, appelé AI Act, a fait l’objet, le 9 décembre 2023 lors des trilogues (1), d’un accord provisoire. Mais des Etats européens, dont la France, ont joué les prolongations dans des réunions techniques (2). La dernière version consolidée (3) de ce texte législatif sur l’IA a été remise le 21 janvier aux Etats membres sans savoir s’ils se mettront d’accord entre eux début février, avant un vote incertain au Parlement européen (4).
Il y a près de trois ans, le 21 avril 2021, la Commission européenne a proposé un règlement visant à établir des règles harmonisées concernant l’intelligence artificielle (IA). Ce règlement européen, appelé AI Act, a fait l’objet, le 9 décembre 2023 lors des trilogues (1), d’un accord provisoire. Mais des Etats européens, dont la France, ont joué les prolongations dans des réunions techniques (2). La dernière version consolidée (3) de ce texte législatif sur l’IA a été remise le 21 janvier aux Etats membres sans savoir s’ils se mettront d’accord entre eux début février, avant un vote incertain au Parlement européen (4).
Contours de l’IA : éléments et précisions
Cette proposition de cadre harmonisé a pour objectif de : veiller à ce que les systèmes d’IA mis sur le marché dans l’Union européenne (UE) soient sûrs et respectent la législation en matière de droits fondamentaux et les valeurs de l’UE ; garantir la sécurité juridique pour faciliter les investissements et l’innovation dans le domaine de l’IA ; renforcer la gouvernance et l’application effective de la législation en matière de droits fondamentaux et des exigences de sécurité applicables aux systèmes d’IA; et faciliter le développement d’un marché unique pour les applications d’IA, sûres et dignes de confiance et empêcher la fragmentation du marché (5). Pour résumer, cette règlementation vise à interdire certaines pratiques, définir des exigences pour les systèmes d’IA « à haut risque »et des règles de transparence, tout en visant à minimiser les risques de discrimination et à assurer la conformité avec les droits fondamentaux et la législation existante. Il reste encore au futur AI Act à être formellement adopté par le Parlement et le Conseil européens pour entrer en vigueur.
L’accord provisoire prévoit que l’AI Act devrait s’appliquer deux ans après son entrée en vigueur, avec des exceptions pour certaines dispositions. Afin de pouvoir saisir l’ampleur des mesures réglementaires, il faut tout d’abord définir ce qu’est réellement l’IA.
La proposition de texte actuelle, tel qu’amendé par le Parlement européen le 14 juin 2023 en première lecture par 499 voix pour, 28 contre et 93 abstentions (6), contient la définition suivante d’un « système d’intelligence artificielle », à savoir « un système automatisé qui est conçu pour fonctionner à différents niveaux d’autonomie et qui peut, pour des objectifs explicites ou implicites, générer des résultats tels que des prédictions, des recommandations ou des décisions qui influencent les environnements physiques ou virtuels ». Dans cette définition amendée, il n’est plus fait référence à l’annexe I contenant une liste de formes d’IA, annexe I contenue dans la proposition initiale de la Commission européenne. En effet un amendement n°708 a supprimé cette annexe I qui contenait trois types d’IA :
• « (a) Approches d’apprentissage automatique, y compris d’apprentissage supervisé, non supervisé et par renforcement, utilisant une grande variété de méthodes, y compris l’apprentissage profond ». Ces techniques permettent aux systèmes d’IA d’apprendre de l’expérience, de reconnaître des modèles et de prendre des décisions intelligentes.
• « (b) Approches fondées sur la logique et les connaissances, y compris la représentation des connaissances, la programmation inductive (logique), les bases de connaissances, les moteurs d’inférence (7) et de déduction, le raisonnement (symbolique) et les systèmes experts ». Les approches d’intelligence artificielle basées sur la logique et les connaissances organisent des données complexes en structures logiques, permettant un raisonnement précis par des systèmes d’IA.
• « (c) Approches statistiques, estimation bayésienne, méthodes de recherche et d’optimisation ». Ces approches permettant l’analyse et l’interprétation précises de données complexes. Ces techniques sont utiles pour identifier des tendances, faire des prédictions, et résoudre des problèmes complexes dans divers secteurs, comme la finance, la logistique et la recherche scientifique.
Face au potentiel de l’IA d’impacter les droits fondamentaux, l’UE vise à réguler son usage viaun marché de confiance, tout en préservant le dynamisme de l’innovation dans ce secteur. Pour atteindre ces objectifs, l’AI Act énonce des dispositions spécifiques applicables aux acteurs de l’IA. Ces dispositions s’articulent autour de deux axes principaux : la gestion des risques et la responsabilité des acteurs.
Risque, de « limité » à « inacceptable »
Ainsi, cette proposition de règles établit des obligations pour les fournisseurs et les utilisateurs en fonction du niveau de risque lié à l’IA. Concernant la gestion des risques, sont définis des niveaux de risque pour les systèmes d’IA, classés de « limité » à « inacceptable ». Ce classement établit des obligations proportionnées en fonction du niveau de risque associé.
• Risque inacceptable. Les systèmes d’IA à risque inacceptable sont des systèmes considérés comme une menace pour les personnes et seront interdits. Par exemple, la proposition de règlement interdit les pratiques suivantes : les systèmes d’IA destinés à évaluer ou à établir un classement de la fiabilité de personnes en fonction de leur comportement social ou de caractéristiques personnelles et pouvant entraîner un traitement préjudiciable de personnes, dans certains contextes, injustifié ou disproportionné (score social) ; ou la manipulation cognitivo-comportementale de personnes ou de groupes vulnérables spécifiques, par exemple, des jouets activés par la voix qui encouragent à des comportements.
Droits des individus et IA éthique
• Risque élevé. Les systèmes d’IA qui ont un impact négatif sur la santé, la sécurité, les droits fondamentaux ou l’environnement (8) seront considérés comme à haut risque et seront divisés en deux catégories (systèmes d’IA utilisés dans des produits tels que jouets, voitures, etc.) et systèmes d’IA relevant de domaines spécifiques qui devront être enregistrés dans une base de données de l’UE (aide à l’interprétation juridique, la gestion de la migration, de l’asile et du contrôle des frontières, etc.). L’annexe III de la proposition de règlement donne une liste des systèmes d’IA à haut risque. Une analyse d’impact sera obligatoire sur les droits fondamentaux, également applicable au secteur bancaire et des assurances. Les citoyens auront le droit de recevoir des explications sur les décisions basées sur des systèmes d’IA à haut risque ayant une incidence sur leurs droits.
• Risque limité. Les systèmes d’IA à risque limité doivent respecter des exigences de transparence minimales qui permettraient aux utilisateurs de prendre des décisions éclairées. Ainsi, les utilisateurs doivent être informés lorsqu’ils interagissent avec l’IA. Cela inclut les systèmes d’IA qui génèrent ou manipulent du contenu image, audio ou vidéo (comme les deepfakes). Par exemple, l’IA générative, telle que ChatGPT, devrait se conformer aux exigences de transparence : indiquer que le contenu a été généré par l’IA, concevoir le modèle pour l’empêcher de générer du contenu illégal, publier des résumés des données protégées par le droit d’auteur utilisées pour la formation. Les modèles d’IA à usage général à fort impact susceptibles de présenter un risque systémique, tels que le modèle d’IA plus avancé GPT-4, et bientôt GPT-5, devraient faire l’objet d’évaluations approfondies et signaler tout incident grave à la Commission européenne. Les droits individuels, eux, sont au cœur de la régulation sur l’IA. L’AI Act accorde une attention particulière aux droits des individus, qui s’articulent autour de quatre axes, afin de garantir une utilisation éthique et respectueuse de l’intelligence artificielle :
• Le droit à la transparence et à l’information vise à assurer que les individus comprennent comment les systèmes d’IA prennent des décisions les concernant.
• Le droit à la non-discrimination vise à protéger les individus contre les décisions automatisées basées sur des critères discriminatoires tels que la race, le genre, l’origine ethnique, la religion ou d’autres caractéristiques protégées. Les systèmes d’IA ne doivent pas conduire à des discriminations injustes ou à des disparités injustifiées.
• Le droit à la sécurité et à la santé souligne l’importance de protéger les individus contre les risques inhérents aux systèmes d’IA. Les entreprises qui développent, mettent sur le marché ou utilisent des systèmes d’IA doivent garantir que ces technologies n’entraînent pas de préjudices physiques ou psychologiques aux individus.
• La protection des données personnelles et de la vie privée. Dans la continuité du RGPD, les entreprises doivent ainsi garantir la confidentialité des données personnelles traitées par les systèmes d’IA. Cela implique une transparence totale sur les données collectées, les finalités du traitement et les mécanismes permettant aux individus de contrôler l’utilisation de leurs informations personnelles.
Les entreprises devront instaurer et suivre un processus itératif de gestion des risques, mettre en place des procédures de gouvernance des données, et garantir la robustesse, l’exactitude, ainsi que la cybersécurité. Les entreprises pourront compter sur les autorités européennes de standardisation qui élaboreront des normes techniques harmonisées pour faciliter la démonstration de la conformité des systèmes d’IA. Les autorités nationales compétentes auront la possibilité de créer des « bacs à sable réglementaires », offrant ainsi un cadre contrôlé pour évaluer les technologies innovantes sur une période déterminée.
Ces regulatory sandboxes reposent sur un plan d’essai visant à garantir la conformité des systèmes et à faciliter l’accès aux marchés auxquels les PME et les start-ups auront une priorité. Avant même la mise sur le marché des systèmes d’IA, les Etats membres devront désigner des « autorités notifiantes ». Cellesci sont désignées afin de superviser le processus de certification des organismes d’évaluation de la conformité. Ces organismes notifiés auront la tâche de vérifier la conformité des systèmes d’IA à haut risque.
« Cnil » européennes, futures gendarmes de l’IA
Il ne faut pas confondre ces entités avec les autorités nationales de contrôle, qui auront la tâche, après la mise en service des systèmes d’IA, de surveiller l’utilisation des systèmes et de s’assurer qu’ils respectent les normes établies par l’AI Act. En France, la Cnil (9) est pressentie. Le règlement comprend également la création du Comité européen de l’IA. Celui-ci sera composé d’un représentant par Etat membre et son rôle sera de conseiller et d’assister la Commission européenne ainsi que les Etats membres dans la mise en œuvre du règlement. L’AI Act prévoit également des mécanismes rigoureux pour garantir la conformité et sanctionner financièrement (10) d’éventuels manquements. @
 L’intelligence artificielle (IA) représente un défi désormais bien connu en matière de droit d’auteur (
L’intelligence artificielle (IA) représente un défi désormais bien connu en matière de droit d’auteur ( L’utilisation de l’intelligence artificielle (IA) dans les domaines artistiques tend à révolutionner la manière dont nous analysons, créons et utilisons les œuvres cinématographiques, littéraires ou encore musicales. Si, dans un premier temps, on a pu y voir un moyen presque anecdotique de créer une œuvre à partir des souhaits d’un utilisateur ayant accès à une IA, elle inquiète désormais les artistes. Les algorithmes et les AI peuvent être des outils très efficaces, à condition qu’ils soient bien conçus et entraînés. Ils sont par conséquent très fortement dépendants des données qui leur sont fournies. On appelle ces données d’entraînement des « inputs », utilisées par les IA génératives pour créer des « outputs ».
L’utilisation de l’intelligence artificielle (IA) dans les domaines artistiques tend à révolutionner la manière dont nous analysons, créons et utilisons les œuvres cinématographiques, littéraires ou encore musicales. Si, dans un premier temps, on a pu y voir un moyen presque anecdotique de créer une œuvre à partir des souhaits d’un utilisateur ayant accès à une IA, elle inquiète désormais les artistes. Les algorithmes et les AI peuvent être des outils très efficaces, à condition qu’ils soient bien conçus et entraînés. Ils sont par conséquent très fortement dépendants des données qui leur sont fournies. On appelle ces données d’entraînement des « inputs », utilisées par les IA génératives pour créer des « outputs ».  « Nous nous trouvons dans une période marquée par le terrorisme et la guerre aux portes de l’UE. Cela s’accompagne d’une guerre de l’information, d’une vague de désinformation et de manipulation et d’ingérence de l’information étrangère. Nous l’avons vu clairement avec le Kremlin après l’agression russe contre l’Ukraine. Nous le voyons maintenant après les actes barbares du Hamas. Nous devons sécuriser notre espace d’information. C’est de la plus grande urgence », a prévenu le 18 octobre à Strasbourg la vice-présidente de la Commission européenne Véra Jourová (photo), en charge des valeurs et de la transparence.
« Nous nous trouvons dans une période marquée par le terrorisme et la guerre aux portes de l’UE. Cela s’accompagne d’une guerre de l’information, d’une vague de désinformation et de manipulation et d’ingérence de l’information étrangère. Nous l’avons vu clairement avec le Kremlin après l’agression russe contre l’Ukraine. Nous le voyons maintenant après les actes barbares du Hamas. Nous devons sécuriser notre espace d’information. C’est de la plus grande urgence », a prévenu le 18 octobre à Strasbourg la vice-présidente de la Commission européenne Véra Jourová (photo), en charge des valeurs et de la transparence. Liberté d’expression, victime collatérale ?
Liberté d’expression, victime collatérale ?  Lors de son tout premier discours annuel sur l’état de l’Union européenne (exercice renouvelé chaque année), le 16 septembre 2020 devant les eurodéputés, la présidente de la Commission européenne, Ursula von der Leyen, avait déclaré qu’il était grand temps de réagir face à la domination des GAFAM et de faire des années 2020 « la décennie numérique » de l’Europe qui doit « montrer la voie à suivre dans le domaine du numérique, sinon elle sera contrainte de s’aligner sur d’autres acteurs qui fixeront ces normes pour nous ». Trois ans après, force est de constater que les acteurs américains dominent encore et toujours Internet.
Lors de son tout premier discours annuel sur l’état de l’Union européenne (exercice renouvelé chaque année), le 16 septembre 2020 devant les eurodéputés, la présidente de la Commission européenne, Ursula von der Leyen, avait déclaré qu’il était grand temps de réagir face à la domination des GAFAM et de faire des années 2020 « la décennie numérique » de l’Europe qui doit « montrer la voie à suivre dans le domaine du numérique, sinon elle sera contrainte de s’aligner sur d’autres acteurs qui fixeront ces normes pour nous ». Trois ans après, force est de constater que les acteurs américains dominent encore et toujours Internet.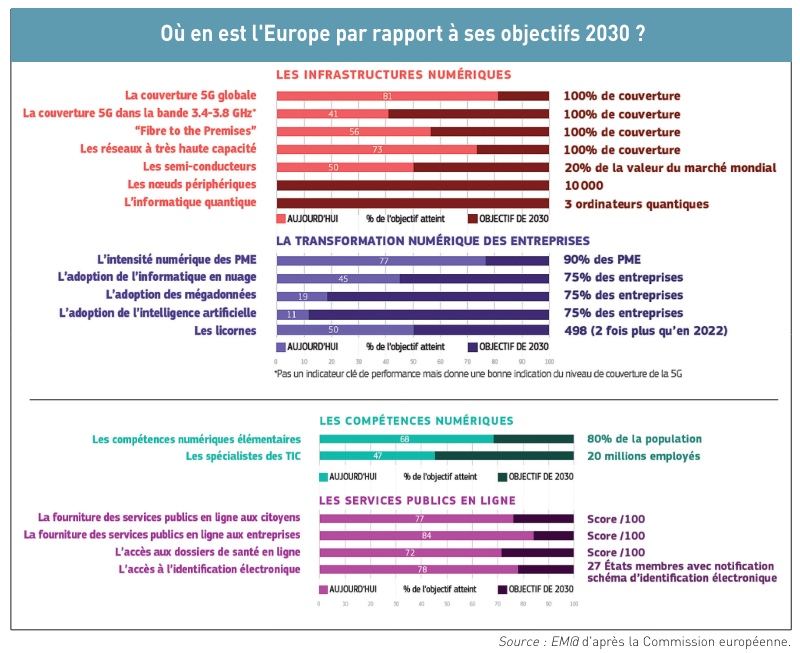
{kind=link}