Fini les geeks qui se retrouvent seuls à écrire des lignes de codes pour développer – « from scratch » (à partir d’une feuille blanche) – des programmes ou des applications. Les développeurs informatiques sont une espèce en voie de disparition. A terme, tout le monde pourra programmer sans coder.
 Imaginez un monde numérique dans lequel tout un chacun pourra créer son application mobile ou ses programmes informatiques, sans connaître le codage ni même avoir entendu parler de langages de programmation tels que les Python, C++ et autres Java. Dans ce futur, pas si lointain, n’importe qui pourra concevoir son logiciel ou son application en fonction de ses besoins ou inventer son jeu vidéo à lui, pour se divertir. Et ce, sans écrire la moindre ligne de code ni faire appel à un programmeur professionnel.
Imaginez un monde numérique dans lequel tout un chacun pourra créer son application mobile ou ses programmes informatiques, sans connaître le codage ni même avoir entendu parler de langages de programmation tels que les Python, C++ et autres Java. Dans ce futur, pas si lointain, n’importe qui pourra concevoir son logiciel ou son application en fonction de ses besoins ou inventer son jeu vidéo à lui, pour se divertir. Et ce, sans écrire la moindre ligne de code ni faire appel à un programmeur professionnel.
De l’autocomplétion passive à l’agentique actif
Votre rêve pourrait rapidement devenir réalité grâce à la déferlante en cours des « IA codeuses », ces intelligences artificielles agentiques capables de coder à votre place en fonction du logiciel, de l’application ou du jeu vidéo que vous souhaitez. Les grands modèles de langage (LLM) dernière génération – Gemini 3 de Google, GPT 5 d’OpenAI, Claude 4.5 d’Anthropic, Large de Mistral AI ou encore Grok 4 de xAI – ont donné naissance à agents codeurs qui génèrent euxmêmes du code, le testent et en assurent sa maintenance. Par exemple, si l’on reprend nos précédents LLM (1), ces IA codeuses s’appellent Antigravity (lancée le 18 novembre 2025), GPT 5.1 High (lancée par OpenAI le 12 novembre), Claude Code (lancée largement le 22 mai), Codestral (lancée par Mistral AI le 29 janvier) ou encore Grok Thinking (lancé par xAI le 17 novembre). L’année 2025 marque donc un tournant et une accélération sur le nouveau marché mondial des IA codeuses, où l’on retrouve bien d’autres concurrents tels que GitHub Copilot (Microsoft), Cursor (Anysphere), Qwen3-Max (Alibaba), Replit Agent (Replit), …
A ce train-là, l’intelligence artificielle (suite) pourrait générer à terme la quasi-totalité des milliards de milliards de lignes de code nécessaires au fonctionnement de nos mondes numériques. Google, qui a présenté le 18 novembre 2025 Antigravity, parle pour le moment d’« une nouvelle ère dans le développement de logiciels assistés par l’IA ». Les développeurs du monde entier – communément appelés les « devs » – connaissent depuis bien longtemps les environnements de développement intégré (ou IDE, pour Integrated Development Environment). Il s’agit d’un logiciel de programmation composé d’au moins un éditeur de code source, d’outils d’automatisation de compilation et d’un débogage, lorsqu’il n’inclut pas aussi de concepteur d’interface graphique utilisateur (GUI), d’un navigateur d’objets (composants-logiciels) ou encore de diagramme de classes (pour la modélisation orientée objet). Mais avec les IA codeuses, l’IDE change de dimension ou, plus précisément, laisse place à une « nouvelle plateforme de développement agentique ». Le fait nouveau est que cette nouvelle génération d’outils intégrés pour le codage n’est plus réservée aux seuls développeurs, mais elle s’adresse in fine à tous. « Nous voulons qu’Antigravity soit la base du développement logiciel à l’ère des agents. Notre vision est de permettre à toute personne, ayant une idée, de vivre le décollage et de la concrétiser », indique Google qui, via sa filiale Google DeepMind dirigée par Demis Hassabis (2), rend Antigravity disponible « en avant-première publique gratuitement, avec des limites tarifaires généreuses sur l’utilisation de Gemini 3 Pro » (3).
D’ailleurs, la filiale d’Alphabet parle de « développement » mais n’utilise pas le thème « développeur »… C’est révélateur. La révolution dans le développement réside dans le passage d’un mode passif d’autocomplétion – où l’IA codeuse se comportait comme un assistant de suggestion dans l’écriture de la suite d’une ligne de code ou de snippets (morceaux de code) – à un mode actif agentique autonome capable de coder de bout-en-bout, en planifiant des tâches complexes, d’exécuter plusieurs étapes de codage sans intervention humaine : écrire les lignes de code, générer des tests, configurer un pipeline, corriger et refactoriser du code existant, interagir avec d’autres outils, …
Les IA codeuses, désormais proactives, peuvent comprendre les objectifs globaux de l’utilisateur – qui n’est plus forcément un développeur – et orchestrer plusieurs étapes, au lieu de se limiter à compléter du code, ligne par ligne. Et cela change tout.
Les IA codeuses from scratch et full stack
Fini les développeurs « from scratch », c’est-à-dire ceux qui partent de zéro (ou d’une page blanche) sans réutiliser de code ou de composants préexistants. Les « devs », qui deviennent des architectes et superviseurs d’IA codeuses plutôt que des « scribes du code », verront leur productivité décupler, voire centupler si ce n’est… milleupler. Les IA codeuses accélèrent et automatisent les développements – jusqu’à donner l’impression d’avoir une compréhension profonde des systèmes. Elles fournissent non seulement ce que l’on appelle chez les devs le framework (ou « cadriciel » en français), à savoir un ensemble cohérent de composants logiciels (bibliothèques, outils, conventions) servant de socle pour construire une application, mais elles peuvent surtout procéder au codage de l’ensemble. L’IA codeuse peut même être « full stack » comme un développeur professionnel peut l’être, autrement dit à même de développer un logiciel, une application ou un site web à la fois en front-end (développement de l’interface graphique utilisateur), en back-end (gestion et traitement des données en coulisses), database comprise (base de données).
 Low-code, no-code, vibe coding et IA codeuses
Low-code, no-code, vibe coding et IA codeuses
A terme, tout le monde pourra donc potentiellement créer sa propre application, sans générer aucune ligne de code. Les techniques de programmation dites « low-code » (avec un peu de code à écrire) et « no-code » (sans aucune ligne de code à écrire) ont préparé les esprits à du développement sans codage ou peu. Mais dans les deux cas, il faut que l’utilisateur passe par une interface graphique ou visuelle telle que : Bubble, Webflow, Zapier ou Make pour le no-code (s’adressant aux non-développeurs) ; OutSystems, Mendix, Appian ou Power Apps pour le low-code (destinés aux développeurs) ; Salesforce Lightning, ServiceNow App Engine ou Microsoft Power Apps (hybrides pour développeurs ou non).
« Le no-code est conçu pour les utilisateurs non techniques. Il permet de créer des applications via des interfaces visuelles, sans écrire une seule ligne de code. C’est idéal pour des tâches simples comme des formulaires, des tableaux de bord ou des automatisations de base, souvent utilisées par les équipes métiers. Le low-code, quant à lui, combine des éléments visuels avec la possibilité d’écrire un peu de code. Il est plus flexible et puissant, permettant de créer des solutions complexes et évolutives. Il s’adresse aux développeurs et équipes techniques, mais peut aussi être utilisé par des profils hybrides – comme les citizen developers », explique à Edition Multimédi@ Andreia Lopes Hermínio (photo), responsable du développement au sein de la division Low-code d’Axians, filiale de Vinci Energies. Mais la démocratisation du code – sans coder soi-même – s’est accélérée avec l’IA, à commencer par le vibe coding, expression apparue depuis le début de l’année 2025 pour désigner une technique de développement logiciel assisté par intelligence artificielle. C’est le principe du « S’il vous plaît… dessine-moi un mouton ! », d’Antoine de SaintExupéry dans « Le Petit Prince », appliqué au développement informatique à partir d’un prompt en langage naturel : « Fais-moi telle app ! », et l’IA génère directement le code fonctionnel et l’application, sans que l’utilisateur ait de connaissances techniques. C’est ce que l’informaticien slovaco-canadien Andrej Karpathy (4), ancien chercheur scientifique et membre fondateur d’OpenAI ainsi qu’ex-directeur de l’IA chez Tesla, appelle le « codage d’ambiance » (vibe coding). « Il existe un nouveau type de codage que j’appelle le “vibe coding”, où l’on se laisse aller à l’ambiance, où l’on adopte les exponentielles et où l’on oublie même l’existence du code. C’est possible parce que les LLM (par exemple, Cursor Composer [d’Anysphere, start-up issue du MIT, ndlr] avec Sonnet [le modèle d’Anthropic, ndlr]) sont de plus en plus performants. De plus, je communique avec Composer via SuperWhisper [modèle de transcription vocale développé par OpenAI, ndlr], ce qui fait que je touche à peine au clavier », avait expliqué Andrej Karpathy en février 2025 sur X (5). Et du vibe coding aux IA codeuses, il n’y a qu’un pas agentique vers l’« agent-first » (l’agent d’abord) où l’IA planifie et exécute de manière autonome des tâches logicielles complexes – de bout en bout.
Mais pas de panique ! Les IA codeuses, comme pour le no-code ou le vibe coding, auront toujours besoin de supervision humaine. Ces agents du codage sont comme des professionnels full stack, mais intégrés dans les workflows des développeurs. De simple créateur de lignes de code, le développeur va devenir un « prompt engineer », ou superviseur d’IA codeuse. « Le développeur devient un architecte », souligne Sornin (27 ans), lui-même développeur full stack. Cependant, certains devs pourraient craindre une déqualification de leur expertise, réduite à de la validation ou à du débogage. Le métier de développeur en France concerne environ un demi-million de personnes, parmi plus de 9 millions de développeurs dans l’Union européenne (plus de 45 millions dans le monde). Leur métier est-il en sursis ? La fédération syndicale Uni Europa ICTS dit « se batt[re] pour que l’IA serve les intérêts des travailleurs » (6).
Les développeurs réduits au chômage ?
« Aujourd’hui, l’IA est devenue un véritable compagnon de travail, capable non seulement d’écrire du code, mais aussi de naviguer dans les applications, de tester automatiquement et même de déboguer plus vite que moi, témoigne sur LinkedIn Antoine Martinelli, développeur web et intégrateur IA, basé en Suisse. Le développeur de demain ressemblera davantage à un intégrateur, un responsable de développement, ou un créatif technologique » (7). L’avenir dira si les IA codeuses augmentent la productivité des développeurs, ce que semble contredire pour l’instant une étude du centre de recherche METR (8) selon laquelle « lorsque les développeurs utilisent des outils d’IA, ils prennent 19 % de plus de temps que sans eux – l’IA les ralentit » (9). Pour l’instant… @
Charles de Laubier
 Tobias Holzmüller (photo), le PDG de la Gema, qui est en Allemagne ce que la Sacem est en France, peut être fier du verdict historique obtenu en première instance du tribunal régional de Munich le 11 novembre 2025 : la manière dont OpenAI gère actuellement ChatGPT viole les lois européennes applicables sur le droit d’auteur. « Pour la première fois en Europe, l’argument en faveur de l’utilisation par les systèmes d’IA générative d’œuvres protégées par le droit d’auteur a été examiné juridiquement et statué en faveur des créateurs des œuvres », s’est félicitée la Société pour les droits d’exécution musicale et de reproduction mécanique (Gema).
Tobias Holzmüller (photo), le PDG de la Gema, qui est en Allemagne ce que la Sacem est en France, peut être fier du verdict historique obtenu en première instance du tribunal régional de Munich le 11 novembre 2025 : la manière dont OpenAI gère actuellement ChatGPT viole les lois européennes applicables sur le droit d’auteur. « Pour la première fois en Europe, l’argument en faveur de l’utilisation par les systèmes d’IA générative d’œuvres protégées par le droit d’auteur a été examiné juridiquement et statué en faveur des créateurs des œuvres », s’est félicitée la Société pour les droits d’exécution musicale et de reproduction mécanique (Gema). Pas de Text and Data Mining (TDM)
Pas de Text and Data Mining (TDM)  Le Syndicat national de l’édition (SNE), qui regroupe les grands groupes de maisons d’édition (Hachette Livre, Editis, MediaParticipations, Madrigall, …) parmi plus de 700 membres, a débaptisé ses « Assises du livre numérique » – qui existaient depuis 2008 – pour les renommer « Nouvelles Assises du livre et de l’édition ». Fini ce rendez-vous dédié aux ebooks, place aux questions sur le livre en général et à ses innovations en particulier. Le thème de la première édition de ces nouvelles assises (
Le Syndicat national de l’édition (SNE), qui regroupe les grands groupes de maisons d’édition (Hachette Livre, Editis, MediaParticipations, Madrigall, …) parmi plus de 700 membres, a débaptisé ses « Assises du livre numérique » – qui existaient depuis 2008 – pour les renommer « Nouvelles Assises du livre et de l’édition ». Fini ce rendez-vous dédié aux ebooks, place aux questions sur le livre en général et à ses innovations en particulier. Le thème de la première édition de ces nouvelles assises ( La bataille de l’audience dans le PAF – ce paysage audiovisuel français qui, décidément, n’en finit pas de se délinéariser en streaming, par-delà les fréquences hertziennes de la TNT dont l’audience s’érode (
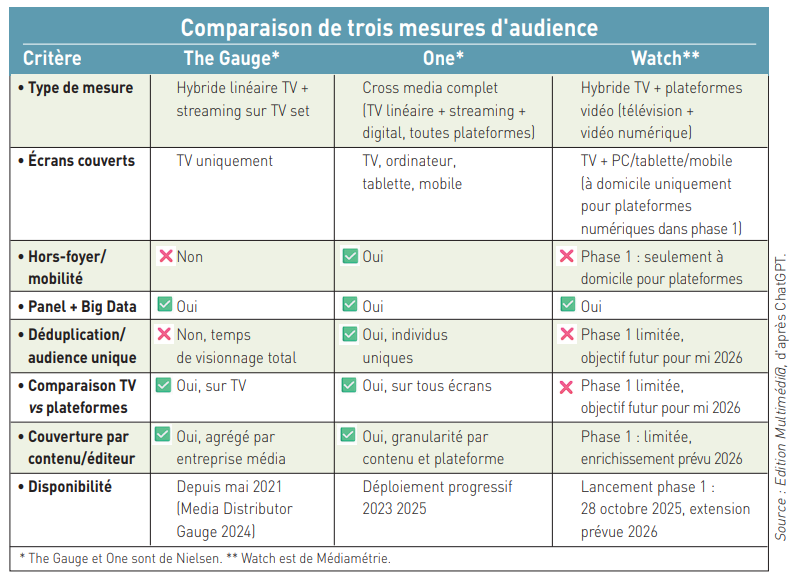
La bataille de l’audience dans le PAF – ce paysage audiovisuel français qui, décidément, n’en finit pas de se délinéariser en streaming, par-delà les fréquences hertziennes de la TNT dont l’audience s’érode (