Adopté par les eurodéputés le 13 mars 2024, l’AI Act – approuvé par les Etats membres en décembre 2023 – va être définitivement voté en plénière par le Parlement européen. Mais des questions demeurent, notamment sur les limites du droit d’auteur face aux intelligences artificielles génératives.
Par Vanessa Bouchara, avocate associée, et Claire Benassar, avocate collaboratrice, Bouchara & Avocats.
 Si l’utilisation des intelligences artificielles (1) est désormais largement répandue, ces techniques et technologies capables de simuler l’intelligence humaine restent au cœur de nombreux questionnements – tant éthiques que juridiques. Alors même que le projet de règlement européen visant à encadrer l’usage et la commercialisation des intelligences artificielles au sein de l’Union européenne, dit AI Act (2), a été adopté en première lecture le 13 mars 2024 par le Parlement européen (3), c’est l’intelligence artificielle générative – IAg, AIG ou GenAI – qui est aujourd’hui sujette à controverse.
Si l’utilisation des intelligences artificielles (1) est désormais largement répandue, ces techniques et technologies capables de simuler l’intelligence humaine restent au cœur de nombreux questionnements – tant éthiques que juridiques. Alors même que le projet de règlement européen visant à encadrer l’usage et la commercialisation des intelligences artificielles au sein de l’Union européenne, dit AI Act (2), a été adopté en première lecture le 13 mars 2024 par le Parlement européen (3), c’est l’intelligence artificielle générative – IAg, AIG ou GenAI – qui est aujourd’hui sujette à controverse.
Droit d’auteur et procès en contrefaçon
A l’origine du débat les concernant, il importe de rappeler que les systèmes d’IAg ont pour particularité de générer du contenu (textes, images, vidéos, musiques, graphiques, etc.) sur la base, d’une part, des informations directement renseignées dans l’outil par son utilisateur, et, d’autre part et surtout, des données absorbées en amont par l’outil pour enrichir et entraîner son système. Les systèmes d’intelligence artificielle générative sont ainsi accusés d’être à l’origine d’actes de contrefaçon, et pour cause : l’ensemble des données entrantes dont ils se nourrissent peuvent potentiellement être protégées par des droits de propriété intellectuelle. Où se situe donc la limite entre l’utilisation licite de ces données et la caractérisation d’un acte de contrefaçon ? Si, par principe, la reproduction de telles données est interdite, le droit européen semble désormais entrouvrir la possibilité d’utiliser celles-ci dans le seul cadre de l’apprentissage de l’IAg.
• L’interdiction de reproduction de données protégées par le droit d’auteur. L’auteur d’une œuvre de l’esprit (4) jouit sur cette œuvre, du seul fait de sa création, de l’ensemble des droits conférés aux auteurs par le Code de la propriété intellectuelle (CPI). A ce titre, l’auteur d’une œuvre peut notamment s’opposer à toute reproduction de celle-ci, c’est-à-dire à toute fixation matérielle quelle qu’elle soit de son œuvre par tous procédés qui permettent de la communiquer au public d’une manière indirecte. Si l’IAg utilise en grande partie des données publiques, se pose tout de même la question de l’utilisation de ces données lorsqu’elles constituent de telles œuvres de l’esprit bénéficiant de la protection offerte par le droit d’auteur. La collecte et l’intégration de telles données dans les outils d’intelligence artificielle constituent-ils toutefois de tels actes de reproduction ? Eu égard à la définition très large du droit de reproduction, il semblerait qu’il faille répondre à cette question par la positive. En effet, la définition qui en est donnée par le législateur incite à considérer qu’en principe, tout acte de reproduction d’une œuvre doit faire l’objet d’une autorisation préalable de son auteur.
Aussi, en l’absence d’autorisation de la part de leurs auteurs, l’intégration des données d’apprentissage protégées par le droit d’auteur dans l’outil d’IAg pourrait aisément matérialiser un acte de contrefaçon par reproduction. C’est d’ailleurs à ce titre que plusieurs procédures sont en cours aux Etats-Unis. Plusieurs recours collectifs ont dernièrement été déposés en 2023 contre OpenAI et Microsoft, notamment par un regroupement d’écrivains américains – soutenus par la Authors Guild (5) – qui soutiennent que l’algorithme entraînant le robot ChatGPT manie leurs œuvres en violation de leurs droits d’auteur. Le New York Times a lui aussi porté plainte contre OpenAI et Microsoft (6). Il en est de même pour la banque d’images Getty Images qui accuse l’outil Stable Diffusion, développé par Stability AI, de violer ses droits d’auteur. Les procès se multiplient contre les IAg. Si la législation applicable est toute autre aux Etats-Unis, il nous semble toutefois que le dénouement des litiges en cours puisse potentiellement nous aiguiller sur le possible positionnement des juges français.
Exceptions, citations, extraits, …
• Intelligence artificielle générative, fair use et exception de courte citation. Si les défendeurs outre Atlantique excipent généralement du concept de fair use, lequel permet l’utilisation loyale d’une œuvre par un tiers, les exceptions au droit d’auteur en France sont strictement délimitées et encadrées par les dispositions du CPI. Aussi, si les droits conférés aux auteurs d’une œuvre de l’esprit sont particulièrement étendus, le législateur les a de longue date assortis d’une liste exhaustive conséquente d’exceptions venant faire obstacle aux droits d’auteur. Parmi celles-ci, à défaut de fair use, certains entendent ainsi défendre l’IAg sur la base de l’exception de courte citation, permettant à tout tiers d’exploiter de courts extraits de l’œuvre dans la mesure où cette exploitation serait notamment justifiée par le caractère pédagogique, scientifique ou d’information de l’œuvre à laquelle elles sont incorporées. Seulement, encore faut-il que le tiers invoquant cette exception indique clairement le nom de l’auteur et la source. Ce que les outils d’IAg ne font pas, et ne peuvent pas faire eu égard à la masse de données sur laquelle se fonde leur entraînement, et surtout au regard du recoupement de l’ensemble de ces informations, lequel rend presque impossible de sourcer chacun des auteurs dont les œuvres sont utilisées.
Fouille de textes et de données limitée
L’évolution des techniques utilisées rend ainsi indispensable l’évolution du droit actuel et de la jurisprudence qui en découlera.
• La limitation du droit d’auteur pour la fouille de textes et de données. Sans même anticiper l’arrivée fulgurante de l’intelligence artificielle au début des années 2020, le législateur européen est venu introduire en 2019 – via la directive « Droit d’auteur dans le marché unique numérique » (7) – une nouvelle exception au droit d’auteur en autorisant la fouille de textes et de données (« text and data mining » ou TDM), laquelle trouve ainsi à s’appliquer lorsque les reproductions d’œuvres réalisées ne remplissent pas toutes les conditions de l’exception pour les actes de reproduction provisoires. Seulement, les défenseurs de l’IAg se sont engouffrés dans cette brèche et ont entendu appliquer cette exception à la collecte et à la reproduction des données disponibles en ligne par les systèmes d’intelligence artificielle, afin de légitimer leur utilisation par ces derniers.
C’est ainsi, dans cette logique, que l’AI Act s’approprie le texte de 2019 et applique l’exception aux fins de fouille de textes et de données aux outils d’IAg. Néanmoins, exception à l’exception, le texte prévoit que tout auteur peut anticiper l’utilisation de ses œuvres par l’IA et s’opposer à cette exploitation en l’indiquant par tout moyen (droit de retrait ou opt out), auquel cas l’exception de « text and data mining » ne trouvera plus à s’appliquer. En pareille hypothèse, les systèmes d’IA seront ainsi à nouveau soumis l’obligation d’obtenir l’autorisation expresse de l’auteur afin de procéder à l’exploration de textes et de données sur ses œuvres de façon licite. Pour autant, le considérant 105 de l’AI Act, précise que les détenteurs de droits peuvent choisir de réserver leurs droits sur leurs œuvres ou autres objets pour empêcher l’exploration de texte et de données, « sauf si cela est fait à des fins de recherche scientifique ». Et dans l’article 2 du même AI Act, le sixième point prévoir que « le présent règlement ne s’applique pas aux systèmes d’IA ou aux modèles d’IA, y compris leur production, spécifiquement développés et mis en service aux seules fins de la recherche et du développement scientifiques ».
Nous nous interrogeons toutefois sur la pertinence de ce système d’« opt out » proposé aux auteurs, dans la mesure où il apparaît difficile – voire impossible – de contrôler son respect par les outils d’IA. En effet, comment un auteur peut-il contrôler que son œuvre n’est pas utilisée pour entraîner une intelligence artificielle ? A charge pour l’AI Office – le Bureau européen de l’IA créé par l’AI Act (8) – de rendre public un « résumé des contenus utilisées pour l’entraînement » de chaque IA à usage général (considérants 107 et 108 de l’AI Act, et articles 53d et 56b).
En dépit de sa volonté protectrice, et alors même qu’il n’est pas entré en vigueur, l’AI Act semble donc d’ores et déjà confronté aux difficultés inhérentes aux avancées techniques issues de l’intelligence artificielle.
• Contenu généré par l’IAg et contrefaçon. Cela étant, quand bien même la fouille de données est autorisée en vertu du droit européen, cette exception reste cantonnée au seul entraînement des systèmes d’IA, et ne permet pas pour autant à l’outil de générer en fin de processus des données contrefaisantes. Aussi, dans la mesure où les données générées reproduiraient à tout le moins en partie les caractéristiques originales des données d’entraînement, elles ne pourront pas être exploitées sans l’autorisation préalable des auteurs des données d’entraînement, sauf à caractériser un acte de contrefaçon. En effet, il n’est en pratique jamais exclu que l’on puisse reconnaître tout ou partie des éléments issus des données entrantes, et il apparaît ainsi en théorie probable que des contrefaçons par imitation puissent être caractérisées. Néanmoins, dans quelle mesure l’utilisateur de l’IAg sera-t-il averti que la donnée générée contrefait une œuvre antérieure ?
Quid de la rémunération des contenus ?
S’il existe nécessairement une limite au-delà de laquelle les tribunaux pencheront en faveur de la contrefaçon, il est fort à parier que les utilisateurs des outils d’IAg la franchiront bien avant les développeurs à l’origine de ces outils. Les interrogations restent en tout cas nombreuses, comme en témoignent les deux missions lancées en France le 12 avril dernier par le Conseil supérieur de la propriété littéraire et artistique (CSPLA), d’une part sur la rémunération des contenus culturels utilisés par les IA (9) et d’autre part sur la mise en œuvre de l’AI Act (10). @
 Claude d’Anthropic sera-t-elle l’IA générative qui pourra détrôner ChatGPT d’OpenAI ? L’avenir dira si la fable du lièvre et de la tortue s’appliquera à ces deux concurrents Alors que ChatGPT d’OpenAI a été lancé le 30 novembre 2022 avec le succès médiatique planétaire que l’on connaît (1), son concurrent Claude d’Anthropic n’a pas dit son dernier mot depuis son lancement le 14 mars 2023 dans une relative indifférence générale (2). Mais c’était sans compter sur Amazon qui a annoncé le 25 septembre 2023 injecter 4 milliards de dollars dans la start-up cofondée par Dario Amodei (photo de gauche)et sa sœur Daniela Amodei (photo de droite), respectivement directeur général et présidente (3). Dans la course mondiale aux IA génératives, Claude fait figure de tortue par rapport au lièvre ChatGPT. Ce qui laisse un espoir pour Anthropic, la start-up qui développe le premier, de rattraper son retard par rapport à OpenAI, à l’origine du second.. Pour l’heure, la tortue Claude fait son chemin aux côtés d’Amazon qui va l’utiliser pour son assistant Alexa.
Claude d’Anthropic sera-t-elle l’IA générative qui pourra détrôner ChatGPT d’OpenAI ? L’avenir dira si la fable du lièvre et de la tortue s’appliquera à ces deux concurrents Alors que ChatGPT d’OpenAI a été lancé le 30 novembre 2022 avec le succès médiatique planétaire que l’on connaît (1), son concurrent Claude d’Anthropic n’a pas dit son dernier mot depuis son lancement le 14 mars 2023 dans une relative indifférence générale (2). Mais c’était sans compter sur Amazon qui a annoncé le 25 septembre 2023 injecter 4 milliards de dollars dans la start-up cofondée par Dario Amodei (photo de gauche)et sa sœur Daniela Amodei (photo de droite), respectivement directeur général et présidente (3). Dans la course mondiale aux IA génératives, Claude fait figure de tortue par rapport au lièvre ChatGPT. Ce qui laisse un espoir pour Anthropic, la start-up qui développe le premier, de rattraper son retard par rapport à OpenAI, à l’origine du second.. Pour l’heure, la tortue Claude fait son chemin aux côtés d’Amazon qui va l’utiliser pour son assistant Alexa.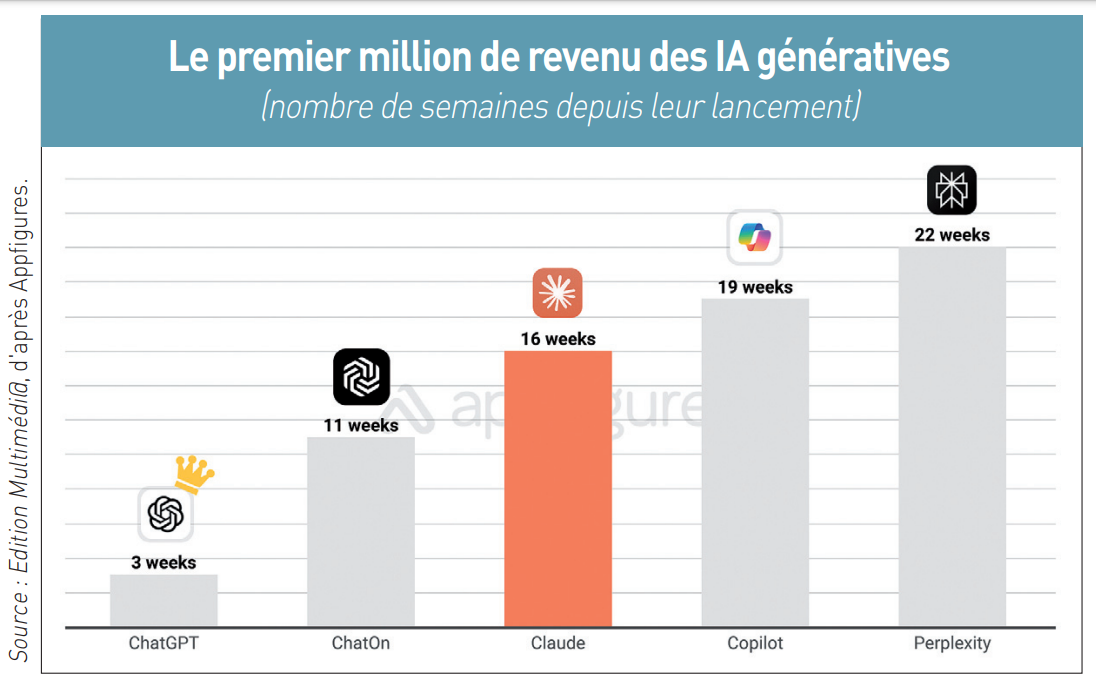 Anthropic a donc plus que jamais une carte à jouer dans la bataille des IA génératives, comme le croit Ariel Michaeli : « Nous estimons que Claude a jusqu’à présent 25.000 abonnés payants. Cela semble beaucoup, mais ChatGPT a ajouté 291.000 nouveaux abonnés payants en juillet [l’IA générative d’OpenAI revendiquant en août plus de 200 millions d’utilisateurs actifs, ndlr]. Pour que Claude ait une chance, il doit apprendre des wrappers et ne pas copier ChatGPT. Si Claude augmente son interface de chat avec des fonctionnalités plus grand public, et s’il promeut son application mobile, alors il pourrait avoir une chance » (6). La monétisation actuelle de Claude sur mobile provient à 48,4 % des Etats-Unis, 6,7 % du Japon, 4,3 % de l’Allemagne, à égalité avec le Royaume-Uni, ou encore de 2,8 % de la Corée du Sud.
Anthropic a donc plus que jamais une carte à jouer dans la bataille des IA génératives, comme le croit Ariel Michaeli : « Nous estimons que Claude a jusqu’à présent 25.000 abonnés payants. Cela semble beaucoup, mais ChatGPT a ajouté 291.000 nouveaux abonnés payants en juillet [l’IA générative d’OpenAI revendiquant en août plus de 200 millions d’utilisateurs actifs, ndlr]. Pour que Claude ait une chance, il doit apprendre des wrappers et ne pas copier ChatGPT. Si Claude augmente son interface de chat avec des fonctionnalités plus grand public, et s’il promeut son application mobile, alors il pourrait avoir une chance » (6). La monétisation actuelle de Claude sur mobile provient à 48,4 % des Etats-Unis, 6,7 % du Japon, 4,3 % de l’Allemagne, à égalité avec le Royaume-Uni, ou encore de 2,8 % de la Corée du Sud.
 L’intelligence artificielle, c’est désormais le foisonnement permanent sur fond de bataille des LLM (Large Language Model), ces grands modèles de langage utilisés par les agents conversationnels et les IA génératives, capables d’exploiter en temps réel des milliards voire des dizaines de milliards de paramètres. Depuis le 30 novembre 2022, date du lancement fracassant de ChatGPT (
L’intelligence artificielle, c’est désormais le foisonnement permanent sur fond de bataille des LLM (Large Language Model), ces grands modèles de langage utilisés par les agents conversationnels et les IA génératives, capables d’exploiter en temps réel des milliards voire des dizaines de milliards de paramètres. Depuis le 30 novembre 2022, date du lancement fracassant de ChatGPT (