Depuis peu, les fournisseurs de systèmes d’intelligence artificielle (IA) font l’objet d’une attention accrue de la part des autorités de contrôle européennes, lesquelles analysent leur conformité au règlement sur la protection des données (RGPD), de l’information des personnes à la base légale.
Par Sandra Tubert, avocate associée et Alicia Forgues, docteure en droit, Algo Avocats
 Après avoir sanctionné OpenAI en décembre 2024 pour ses manquements au RGPD en lien avec son IA générative ChatGPT (1), l’autorité italienne de protection des données – la GPDP (2) – vient cette fois d’ordonner, le 30 janvier dernier (3), le blocage immédiat de l’application et du site web DeepSeek en Italie en raison de manquements présumés au RGPD. Avant d’ordonner la limitation du traitement, la GPDP avait adressé le 28 janvier une demande d’informations à DeepSeek, afin qu’elle précise les données traitées, les finalités poursuivies, leurs bases légales, le lieu de stockage, ainsi que la typologie de données utilisées pour entraîner les modèles d’IA, leurs sources et les modalités d’information des personnes (4).
Après avoir sanctionné OpenAI en décembre 2024 pour ses manquements au RGPD en lien avec son IA générative ChatGPT (1), l’autorité italienne de protection des données – la GPDP (2) – vient cette fois d’ordonner, le 30 janvier dernier (3), le blocage immédiat de l’application et du site web DeepSeek en Italie en raison de manquements présumés au RGPD. Avant d’ordonner la limitation du traitement, la GPDP avait adressé le 28 janvier une demande d’informations à DeepSeek, afin qu’elle précise les données traitées, les finalités poursuivies, leurs bases légales, le lieu de stockage, ainsi que la typologie de données utilisées pour entraîner les modèles d’IA, leurs sources et les modalités d’information des personnes (4).
Modèles d’IA, systèmes d’IA et données
D’autres « Cnil » européennes ont ouvert des enquêtes. Si le recours à l’IA n’impacte pas véritablement les réponses à apporter à certaines de ces questions, les bases légales de traitement et modalités d’information des personnes posent plus de difficultés lorsqu’il s’agit des traitements mis en œuvre dans le cadre de l’entraînement des modèles d’IA. En effet, ces derniers sont entraînés à l’aide d’un grand nombre de données, parmi lesquelles figurent parfois des données personnelles. Celles-ci se divisent en deux catégories : les données fournies directement par des personnes concernées ou les utilisateurs du système d’IA intégrant le modèle d’IA, auxquelles se rajoutent les données collectées durant l’utilisation du service (données first-party) et les données de non-utilisateurs collectées par web scraping ou grâce à la signature de contrats de licences d’utilisation de contenus (données third-party).
Lorsque le fournisseur se contente d’utiliser des données first-party pour entraîner ses modèles d’IA, le contact direct dont il dispose avec les personnes concernées par le traitement lui permet de les informer de manière classique, notamment via une politique de confidentialité – à laquelle il sera renvoyé depuis un formulaire de collecte ou un courriel – qui devra être précise et claire sur les finalités d’entraînement des modèles (notamment en distinguant l’information portant sur l’entraînement des modèles des autres traitements). A l’inverse, s’il utilise également (suite)
des données third-party, le fournisseur fait face à une difficulté, celle d’identifier un moyen approprié pour informer les personnes concernées de l’utilisation de leurs données à des fins d’entraînement des modèles d’IA. Sur ce point, la décision de sanction de 15 millions d’euros rendue en Italie par la GPDP à l’encontre d’OpenAI contient quelques enseignements. Elle y rappelle qu’elle avait, en avril 2023, ordonné à OpenAI un certain nombre de mesures pour se conformer à l’obligation d’information du RGPD. Selon la GPDP, OpenAI devait non seulement publier une mention d’information sur son site Internet explicitant clairement les finalités d’entraînement des modèles, mais aussi mettre à disposition des personnes un outil permettant d’exercer leurs droits (notamment d’opposition). Le fournisseur de ChatGPT devait également et surtout mener une campagne non promotionnelle à la radio, dans les journaux et à la télévision, dont le contenu aurait dû être validé par l’autorité. Objectif : que les utilisateurs et non-utilisateurs soient clairement sensibilisés à l’utilisation de leurs données à des fins d’entraînement des modèles d’IA et aux droits dont ils disposent, afin qu’ils puissent pleinement les exercer. Cette dernière modalité d’information demandée questionne sur les motivations entourant cette mesure (volume de personnes et de données concernées ? méconnaissance de ces traitements par le grand public en 2023 ?). En effet, cette mesure semble difficilement transposable à l’ensemble des acteurs entraînant des modèles d’IA.
En France, la Commission nationale de l’informatique et des libertés (Cnil) propose dans ses fiches IA (5) d’autres pistes pour informer les personnes. Première suggestion : s’appuyer sur le diffuseur des données (celui qui les a collectées initialement auprès des personnes) pour fournir une information complète, étant précisé que la seule mention d’une ré-exploitation par des tiers est insuffisante et qu’il convient, au contraire, d’indiquer que les données seront utilisées afin de développer un système d’IA et d’en désigner nommément le fournisseur.
Exception à l’information individuelle
Deuxième suggestion de la Cnil : rendre les informations disponibles publiquement sur un site web ou panneau d’affichage, sans procéder à une information individuelle, en s’appuyant sur l’exception prévue par le RGPD (à savoir l’information individuelle se révèlerait impossible ou exigerait des efforts disproportionnés (6)). Sur ce point, il conviendra alors de documenter le caractère disproportionné, suite à une mise en balance entre les efforts exigés – comme l’absence de coordonnées des personnes, le nombre de personnes concernées, les coûts de communication – et l’atteinte portée à la vie privée des personnes, notamment le caractère intrusif du traitement. La Cnil précise que l’information générale devra alors indiquer les sources précises utilisées pour constituer la base de données d’entraînement (ou a minima les catégories de sources lorsqu’elles sont trop nombreuses) ainsi que les moyens pour contacter le diffuseur auprès duquel les données ont été récupérées (7).
Intérêt légitime et ses limites : incertitude
Au-delà de l’information, l’entraînement des modèles d’IA questionne sur l’identification de la base légale parmi les six options inscrites dans le RGPD (8). Dans sa décision à l’encontre d’OpenAI, la GPDP a relevé un manquement sur ce point, lui reprochant une réflexion insuffisante sur le sujet, matérialisée par le fait qu’au cours de la procédure, la société a évoqué à la fois l’intérêt légitime et l’exécution du contrat comme base légale de son traitement d’entraînement des modèles d’IA. La GPDP rappelle ainsi aux fournisseurs de systèmes d’IA leur obligation d’identifier la base légale du traitement en amont de la mise en œuvre de ces traitements et de documenter leur analyse si l’intérêt légitime est retenu. Malheureusement, elle n’explore pas plus en profondeur la légitimité de fonder de tels traitements sur l’intérêt légitime ou ses limites, laissant les fournisseurs dans l’incertitude. Or, l’intérêt légitime est la base légale vers laquelle se tournent majoritairement les fournisseurs de système d’IA.
Ceci s’explique principalement par les cas restreints dans lesquels il est possible de fonder les traitements d’entraînement des modèles sur le consentement ou l’exécution du contrat. Cette dernière est souvent rapidement exclue, puisqu’une interprétation stricte en est retenue par les autorités et la CJUE et qu’elle ne peut être utilisée qu’en présence d’un contrat entre le fournisseur du système d’IA et les personnes concernées, pour des traitements objectivement indispensables à l’exécution des obligations prévues par ce contrat. Le consentement peut, quant à lui, être mobilisé par les fournisseurs utilisant des données firstparty, mais n’est pas véritablement disponible pour ceux qui entraînent leurs modèles d’IA avec des données third-party. Dès lors, le recours à l’intérêt légitime pour entraîner des modèles se généralise, même si cette démarche est critiquée, notamment par l’association Noyb (9).
Face à cette incertitude, l’autorité irlandaise (DPC) a émis une demande d’avis auprès du Comité européen de la protection des données (EDPB) en septembre 2024. La DPC souhaitait obtenir des renseignements sur la façon dont un responsable du traitement peut démontrer le bien-fondé de l’intérêt légitime en tant que base légale de traitement pour le développement de modèles d’IA (10). En réponse, l’EDPB a adopté en décembre dernier un avis (11), assez théorique (sans éclaircissements inédits), dans lequel il rappelle et présente les grandes notions et critères à prendre en compte en lien avec les trois conditions cumulatives pour documenter le fait qu’un traitement puisse être fondé sur l’intérêt légitime. L’EDPB y propose néanmoins quelques exemples de mesures souhaitables pour atténuer les risques identifiés lors de la balance des intérêts (pseudonymisation des données d’entraînement, masquage des données personnelles ou leur substitution par des données synthétiques, mise en place d’un délai entre la constitution de la base et l’entrainement des modèles pour permettre l’exercice des droits, …). Pour les données collectées par web scraping, l’EDPB propose des mesures spécifiques (exclure certaines catégories de données ou certaines sources, créer des listes d’opposition gérées par le fournisseur de systèmes d’IA, …). La DPC a salué l’avis rendu, de même que la Cnil, dont les travaux préexistants sur le sujet (qui apportent un éclairage complémentaire et plus concret) ne sont pas contredits (12). En dépit des recommandations figurant dans ces avis, les difficultés liées au recours à l’intérêt légitime dans un contexte d’entraînement des modèles d’IA sont mises en lumière par l’avertissement rendu par la GPDP, le 27 novembre 2024, à l’encontre de l’éditeur de presse Gedi (13). Celui-ci avait conclu un contrat avec OpenAI relatif à la communication d’archives de journaux pour permettre à ce dernier d’entraîner ses modèles d’IA et de mettre à disposition les contenus de presse de Gedi accompagnés d’un résumé, en temps réel, sur ChatGPT (14). En effet, bien que Gedi ait réalisé une analyse d’impact sur la protection des données, dans laquelle il indiquait fonder à la fois ses traitements et ceux d’OpenAI sur l’intérêt légitime, la GPDP a mis en lumière plusieurs difficultés liées à cette position (15).
Affaire « Gedi » : le cas des archives de presse
La première est la présence dans ces archives d’un volume important de données personnelles, notamment sensibles ou relatives à des infractions. L’autorité italienne rappelle alors que la base légale de l’intérêt légitime ne peut pas, à elle seule, légitimer le traitement de telles données sensibles et qu’il est nécessaire d’identifier, en plus, une des exceptions prévues par le RGPD (16). La seconde est relative à l’information des personnes et à leurs attentes raisonnables. La GPDP estime en effet que les personnes dont les données figurent dans ces archives de journaux ne peuvent pas s’attendre à une telle communication à OpenAI et que l’ajout prévu dans la politique de confidentialité de Gedi (non encore publié) s’adresse aux utilisateurs enregistrés de ses journaux et non aux personnes mentionnées dans les articles transmis. @
 N’appelez pas cette troisième édition « AI Safety Summit » (Sommet sur la sécurité de l’IA) comme ce fut le cas pour la première édition qui s’était tenue au Royaume-Uni en 2023 (
N’appelez pas cette troisième édition « AI Safety Summit » (Sommet sur la sécurité de l’IA) comme ce fut le cas pour la première édition qui s’était tenue au Royaume-Uni en 2023 ( « Etats-Unis, capitale mondiale de l’IA » (Trump)
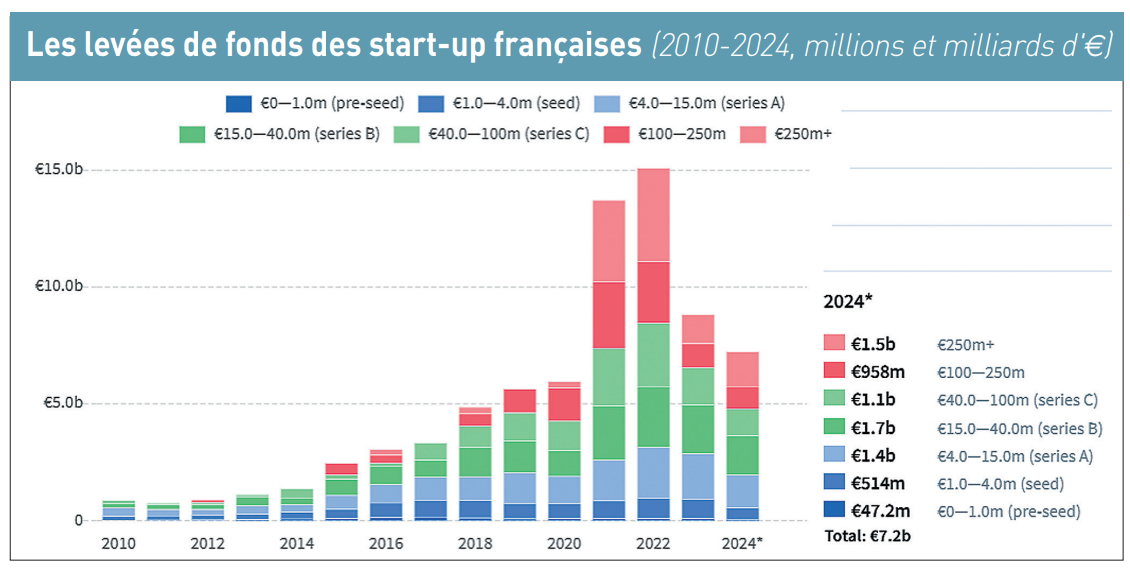
« Etats-Unis, capitale mondiale de l’IA » (Trump)  Les premiers calculs sur les levées de fonds enregistrées sur l’année 2024 par les start-up de la « French Tech » font état d’un total d’environ 7,2 milliards d’euros. C’est plus ou moins un milliard de moins que l’année précédente, et bien loin des quelque 15 milliards d’euros levés en 2022 au sortir de la crise sanitaire, pour ne pas dire moitié moins que ce record. Cette chute de – 12 % sur un an des capitaux investis dans les jeunes pousses innovantes, bien qu’amortie, est paradoxale au regard de la révolution de l’intelligence artificielle (IA), des besoins en mobilité ou encore de l’essor de la fintech.
Les premiers calculs sur les levées de fonds enregistrées sur l’année 2024 par les start-up de la « French Tech » font état d’un total d’environ 7,2 milliards d’euros. C’est plus ou moins un milliard de moins que l’année précédente, et bien loin des quelque 15 milliards d’euros levés en 2022 au sortir de la crise sanitaire, pour ne pas dire moitié moins que ce record. Cette chute de – 12 % sur un an des capitaux investis dans les jeunes pousses innovantes, bien qu’amortie, est paradoxale au regard de la révolution de l’intelligence artificielle (IA), des besoins en mobilité ou encore de l’essor de la fintech.