Start-up cofondée en août 2022 par l’Indo-américain Aravind Srinivas, le Biélorusse Denis Yarats et les Américains Andy Konwinski et Johnny Ho, Perplexity AI monte en charge avec l’ambition de mettre un terme au quasi-monopole de Google dans la recherche sur le Web, grâce à son agent IA combiné à un moteur de réponse.
 « Perplexity n’est pas un chabot. C’est un outil », avertit sur son site web (1) la licorne californienne Perplexity AI – qui n’est pas encore cotée en Bourse mais qui est, en moins de trois ans d’existence, déjà valorisée près de 10 milliards de dollars… pour l’instant. Son « outil » n’est autre qu’un agent conversationnel basé sur l’intelligence artificielle combiné avec un moteur de réponse. L’outil « AI-native search » de Perplexity est à la start-up Perplexity AI ce que le moteur de recherche Google est au géant du Net devenu monopolistique. Le premier rêve de détrôner le second, coûte que coûte.
« Perplexity n’est pas un chabot. C’est un outil », avertit sur son site web (1) la licorne californienne Perplexity AI – qui n’est pas encore cotée en Bourse mais qui est, en moins de trois ans d’existence, déjà valorisée près de 10 milliards de dollars… pour l’instant. Son « outil » n’est autre qu’un agent conversationnel basé sur l’intelligence artificielle combiné avec un moteur de réponse. L’outil « AI-native search » de Perplexity est à la start-up Perplexity AI ce que le moteur de recherche Google est au géant du Net devenu monopolistique. Le premier rêve de détrôner le second, coûte que coûte.
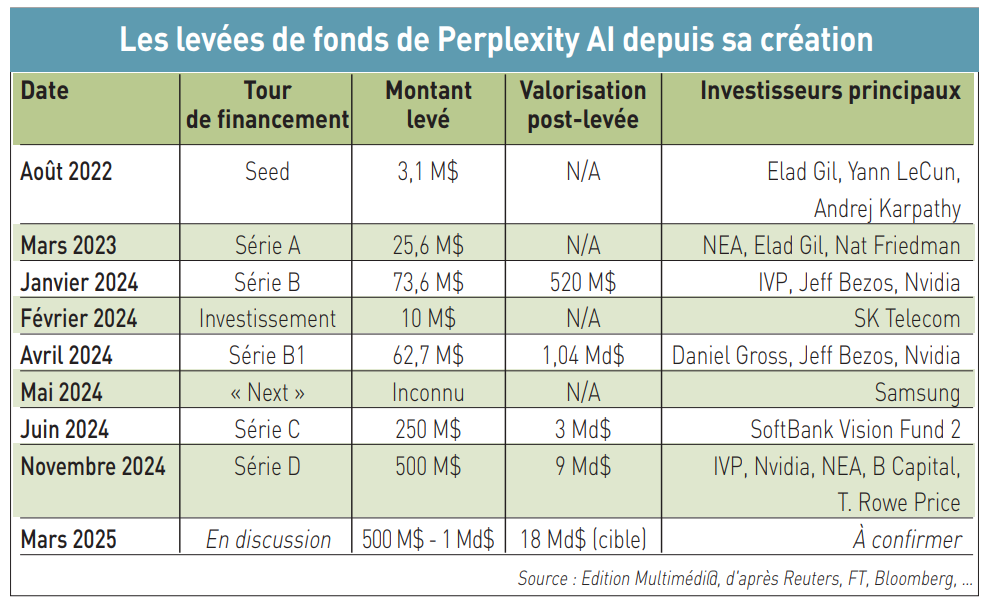
Depuis qu’ils ont cofondé en août 2022 leur entreprise à San Francisco (Californie), Aravind Srinivas (photo), Denis Yarats, Andy Konwinski et Johnny Ho ont levé à ce jour environ 675 millions de dollars. Il y a un an, la start-up devenait une licorne à la faveur d’une quatrième levée de fonds – en avril 2024 (auprès notamment de Jeff Bezos et de Nvidia) – portant sa valorisation à un peu plus de 1 milliard de dollars. Deux autres tours de table – en juin (auprès de Softbank) et la dernière en date en novembre 2024 (auprès de Nvidia entre autres) – ont fait exploser sa valorisation à respectivement 3 milliards puis 9 milliards de dollars. Et encore, cela ne tient pas compte d’un investissement non divulgué du fonds Samsung Next en mai 2024 (voir tableau page suivante).
Accord avec Motorola, et bientôt Samsung ?
Sur sa lancée, Perplexity AI discute actuellement avec des investisseurs d’une nouvelle levées de fonds qui, d’après Bloomberg, se situerait entre 500 millions de dollars et 1 milliard de dollars, ce qui pourrait doubler sa valorisation, à 18 milliards de dollars (2). L’Indo-américain Aravind Srinivas (directeur général), le Biélorusse Denis Yarats (directeur technique) et les Américains Andy Konwinski (président) et Johnny Ho (directeur de la stratégie) sont décidé à mettre les bouchées doubles pour s’attaquer à la position dominante de la filiale d’Alphabet. C’est du côté du numéro un mondial (3) des smartphones – Samsung Electronics, déjà investisseur depuis un an dans Perplexity AI – que se trouve la clé de ses ambitions face à Google, tout en rivalisant avec le nouvel entrant de la première heure, OpenAI et son « ChatGPT Search » (4) lancé fin octobre 2024. Des négociations sont en cours avec le fabricant sud-coréen des Galaxy, fonctionnant tous – ironie de l’histoire – sur (suite)
le système d’exploitation le plus répandu au monde dans les smartphones, Android de… Google.
Préinstallé sur des millions de smartphones
Par ailleurs, Perplexity AI vient de conclure un accord mondial avec un autre fabricant de téléphones mobiles, de moindre envergure celui-là, Motorola, filiale du chinois Lenovo depuis 2014. « Perplexity sera préinstallé sur des millions de smartphones dans le monde [dont les modèles pliables Razr, ndlr], offrant aux utilisateurs de Motorola un accès direct à notre moteur de réponse et à notre assistant », a annoncé le 27 avril (5) la licorne. Mais c’est avec Samsung que le petit rival de Google pourrait devenir grand, le sudcoréen détenant en 2024 une part de marché mondiale des smartphones de 18,1 %, d’après IDC – contre seulement 3,7 % pour Motorola.
Préinstaller Perplexity sur les millions de Galaxy vendus chaque année (223,5 millions d’unités vendues l’an dernier) lui offrirait une véritable rampe de lancement. « Les termes pourraient inclure l’offre de Perplexity comme une option d’assistant IA par défaut ou en préchargeant l’application Android au démarrage sur les téléphones. Samsung pourrait également promouvoir fortement l’assistant comme une option dans le Galaxy Store, où les utilisateurs téléchargent des applications », ont indiqué à Bloomberg le 17 avril des personnes au fait des discussions (6). Ni Perplexity ni Samsung n’ont souhaité commenter ces informations. Des sources de l’agence de presse new-yorkaise ont en outre indiqué que, après le premier investissement via son Next il y a un an, « Samsung envisage de faire un autre investissement dans Perplexity dans un proche avenir » et dans le cadre du nouveau tour de table financier que la licorne de San Francisco tente de constituer pour lever jusqu’à 1 milliard de dollars. Si les négociations entre Perplexity AI et Samsung aboutissaient, Google pourrait se sentir doublé, lui qui a noué dès janvier 2024 un partenariat d’envergure avec le fabricant mondial des smartphones. Ainsi, Gemini Pro et Imagen 2 de Google DeepMind – respectivement le modèle IA multimodal et l’IA générative d’images – sont accessibles sur des millions de Galaxy. Et lors du procès antitrust en cours aux Etats-Unis contre Google accusé de « monopole illégal », procès où Perplexity a d’ailleurs été appelé à donner son avis (7)), des témoignages recueillis montrent que la filiale d’Alphabet paie chaque mois à Samsung « une énorme somme d’argent » pour préinstaller son application IA, Gemini, sur les appareils Samsung.
Perplexity AI n’est pas le seul à essayer de trouver avec Samsung un accord mondial pour concurrencer Google dans la « Galaxy » Samsung : Microsoft, OpenAI et Meta, dont la messagerie WhatsApp accueille Perplexity depuis le 26 avril (8), ont eux aussi approché le fabricant sud-coréen, pour tenter d’être aux premières loges. « Perplexity AI est dirigé par une équipe fondatrice de quatre personnes aux compétences diverses mais complémentaires. Aravind Srinivas, le PDG, apporte une riche expertise en IA acquise chez OpenAI, mettant en évidence un leadership fort et une vision stratégique pour l’entreprise [Denis Yarats, lui, fut chercheur en AI durant six ans chez Facebook, ndlr]. Leur expérience collective couvre l’IA, le développement commercial, l’ingénierie et les technologies perturbatrices, ce qui les positionne bien pour relever les défis du développement d’un moteur de recherche de nouvelle génération », expliquait admiratif Samsung Next il y a un an (9).
Perplexity, candidat au rachat de TikTok US
En mars dernier, Aravind Srinivas a indiqué sur LinkedIn (10) que la licorne a franchi la barre des 100 millions de dollars de chiffre d’affaires annuel. Les quatre cofondateurs ont en outre créé la surprise en se portant candidat au rachat de la filiale américaine de TikTok, que les Etats-Unis pressent la maison mère chinoise ByteDance de céder. « La combinaison du moteur de réponse de Perplexity avec la vaste vidéothèque de TikTok nous permettrait de créer la meilleure expérience de recherche au monde », a assuré le 21 mars la start-up qui propose de « reconstruire l’algorithme de TikTok sans créer de monopole » (11). Donald Trump a donné à ByteDance jusqu’au 19 juin comme nouvelle date limite de vente de TikTok US. La licorne a face à lui d’autres candidats au rachat : Microsoft, Oracle, Frank McCourt ou encore MrBeast. @
Charles de Laubier
 Les ChatGPT, Claude, Perplexity, Meta Ai et bien d’autres intelligences génératives vont devoir mettre la main au portefeuille pour rémunérer équitablement les auteurs et les créateurs lorsqu’elles utilisent leurs œuvres. Trois organismes ont chacun publié leur rapport dans le courant du mois de mai 2025 : l’US Copyright Office (USCO) aux Etats-Unis le 9 mai, l’Office de l’Union européenne pour la propriété intellectuelle (EUIPO) en Europe le 12 mai et le Conseil supérieur de la propriété littéraire et artistique (CSPLA) en France le 16 mai.
Les ChatGPT, Claude, Perplexity, Meta Ai et bien d’autres intelligences génératives vont devoir mettre la main au portefeuille pour rémunérer équitablement les auteurs et les créateurs lorsqu’elles utilisent leurs œuvres. Trois organismes ont chacun publié leur rapport dans le courant du mois de mai 2025 : l’US Copyright Office (USCO) aux Etats-Unis le 9 mai, l’Office de l’Union européenne pour la propriété intellectuelle (EUIPO) en Europe le 12 mai et le Conseil supérieur de la propriété littéraire et artistique (CSPLA) en France le 16 mai. « OpenAI a annoncé en décembre 2024 son intention d’adopter le statut de Public Benefit Corporation (PBC), dans le Delaware, une structure juridique qui permet de concilier objectifs lucratifs et missions d’intérêt général. Cette évolution pourrait faciliter une future entrée en Bourse, bien qu’aucun calendrier précis n’ait été communiqué », a répondu ChatGPT à Edition Multimédi@ sur la future cotation de la célèbre licorne. D’après le chatbotmaison, son PDG Sam Altman (photo) envisage « avec prudence » cette IPO (
« OpenAI a annoncé en décembre 2024 son intention d’adopter le statut de Public Benefit Corporation (PBC), dans le Delaware, une structure juridique qui permet de concilier objectifs lucratifs et missions d’intérêt général. Cette évolution pourrait faciliter une future entrée en Bourse, bien qu’aucun calendrier précis n’ait été communiqué », a répondu ChatGPT à Edition Multimédi@ sur la future cotation de la célèbre licorne. D’après le chatbotmaison, son PDG Sam Altman (photo) envisage « avec prudence » cette IPO ( La Bourse et la vie : modèle hybride
La Bourse et la vie : modèle hybride